How TurboQuant, Custom Silicon, and the Efficiency Revolution Are Quietly Restructuring the $2 Trillion AI Value Chain
Authors:
Felix Kim & Redrob Research Labs
Date:

In March 2026, Google Research published TurboQuant — an algorithm that compresses the KV cache in transformer inference by 6x with zero accuracy loss. The AI industry received it as a welcome efficiency improvement. This paper argues it is something far more consequential: a value chain restructuring event.
TurboQuant, combined with the rapid maturation of custom AI silicon (Google TPU, Amazon Trainium, Microsoft Maia, Meta MTIA) and software optimizations like Mixture-of-Experts and sparse attention, is quietly dismantling the economic logic that has made NVIDIA the most valuable company on Earth. Every efficiency breakthrough reduces the number of GPUs needed per query. Every custom chip reduces the margin NVIDIA extracts per accelerator. Every software optimization shifts value from hardware vendors to orchestration layers.
Corethesis: TurboQuant is not a compression algorithm. It is a value chain restructuring event. Every efficiency breakthrough - TurboQuant (6x), MoE (75%), quantization (75%), sparse attention (50%) - reduces hardware dependency and shifts value from chip/memory vendors to software orchestrators. Combined theoretical gains: 99%. Actual cost reduction realized: ~20%. The difference is absorbed by Jevons Paradox. The beneficiary is not the end user (who gets more capability, not lower cost) but whoever controls the orchestration layer that decides how efficiently hardware is used.
1. TurboQuant: More Than Meets the Eye
In March 2026, Google Research published TurboQuant at ICLR — an algorithm that compresses the KV cache during transformer inference by approximately 6x while achieving up to 8x speedup in attention computation, with negligible accuracy loss. The KV cache is the largest memory bottleneck in LLM inference, growing linearly with context length. At 128K context on a 70B-parameter model, a single user's KV cache consumes approximately 40GB of GPU memory. TurboQuant compresses this to under 7GB.
The industry received TurboQuant as a welcome technical advance. But its significance extends far beyond memory compression. TurboQuant does not reduce the cost of AI for end users. It enables longer contexts, higher concurrency, and more ambitious agentic workflows for existing users. The freed memory is consumed by capability expansion, not price reduction. This is the Jevons Paradox operating at the hardware level.
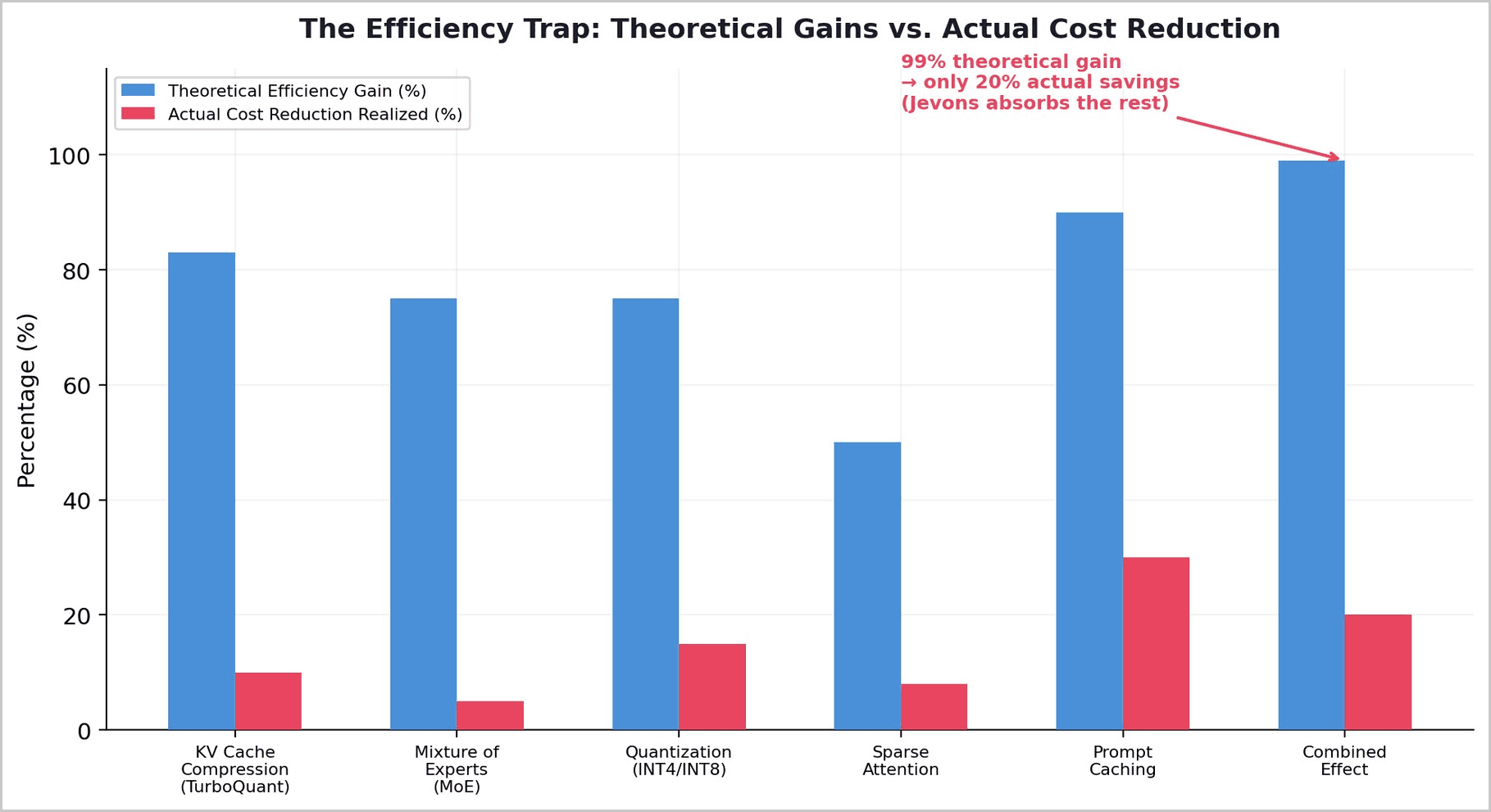
The strategic significance is not what TurboQuant does to memory. It is what TurboQuant does to the value chain. By making memory less of a bottleneck, TurboQuant reduces the leverage of HBM vendors (SK Hynix, Samsung, Micron) and GPU vendors (NVIDIA) whose pricing power derives from scarcity. The value shifts to whoever can best orchestrate the freed capacity.
1.1 The Market Verdict: Memory Stocks Fell
The financial markets understood TurboQuant's significance immediately. On March 25, 2026 — the day after the blog post — Samsung, SK Hynix, and Micron stock prices fell. The selloff was later called an overreaction — TurboQuant does not affect training workloads, which consume the bulk of HBM. But the direction of the signal was correct: software efficiency is reducing hardware leverage.
Morgan Stanley's analysis was revealing: TurboQuant allows systems to handle 4-8x longer context windows or significantly larger batch sizes on the same hardware. The conclusion: it is less about reducing total memory needs and more about improving efficiency. This is precisely the Jevons dynamic — efficiency does not shrink the market, it restructures who captures value within it.
1.2 NVIDIA's Counter-Move: KVTC
NVIDIA understood the threat. At the same ICLR 2026 conference, NVIDIA presented KVTC (KV Cache Transform Coding) — achieving up to 20x compression, significantly more aggressive than TurboQuant's 6x. But the tradeoff is instructive: KVTC requires calibration data and offline processing, while TurboQuant is "data-oblivious" — deployable instantly on any model with no calibration overhead. NVIDIA is fighting to keep the efficiency gains within its ecosystem. Google designed TurboQuant to work on any hardware — including TPUs, where it provides the most benefit.
One detail the research community noted: TurboQuant's math lands within a factor of roughly 2.7 of the Shannon limit — the theoretical ceiling for compression efficiency at a given bit-width. The easy gains from KV cache compression are mostly spoken for. This means TurboQuant is not the beginning of a trend. It is close to the end of what KV cache compression can achieve — making its value chain impact a one-time structural shift, not an ongoing erosion.
The market signal: Memory chip stocks fell the day TurboQuant was published. NVIDIA rushed its own 20x compression algorithm to ICLR 2026. The market understood what most technologists missed: TurboQuant is a value chain restructuring event disguised as a compression algorithm.
2. The Custom Silicon Revolt
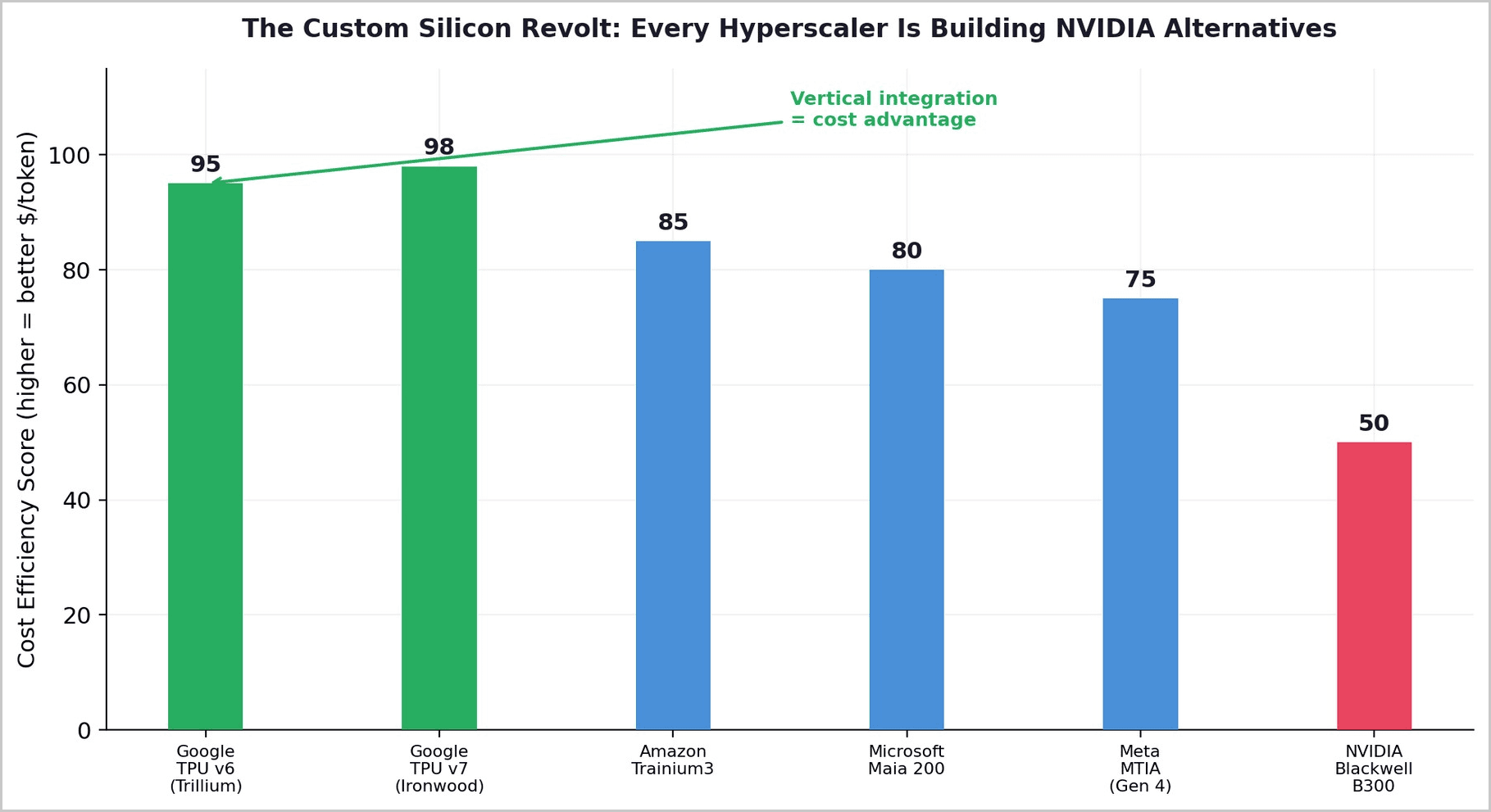
TurboQuant does not exist in isolation. It is one front in a broader offensive against NVIDIA's dominance. Every major hyperscaler is now building custom AI accelerators designed to reduce dependence on NVIDIA GPUs. Google's TPU v6 (Trillium) delivers 4.7x performance over its predecessor with 60-65% less power consumption than equivalent GPU configurations. Amazon's Trainium3 provides 2.52 petaflops of FP8 compute. Microsoft's Maia 200 claims 3x the FP4 performance of Trainium3. Meta announced four MTIA chip generations with up to 25x compute gains.
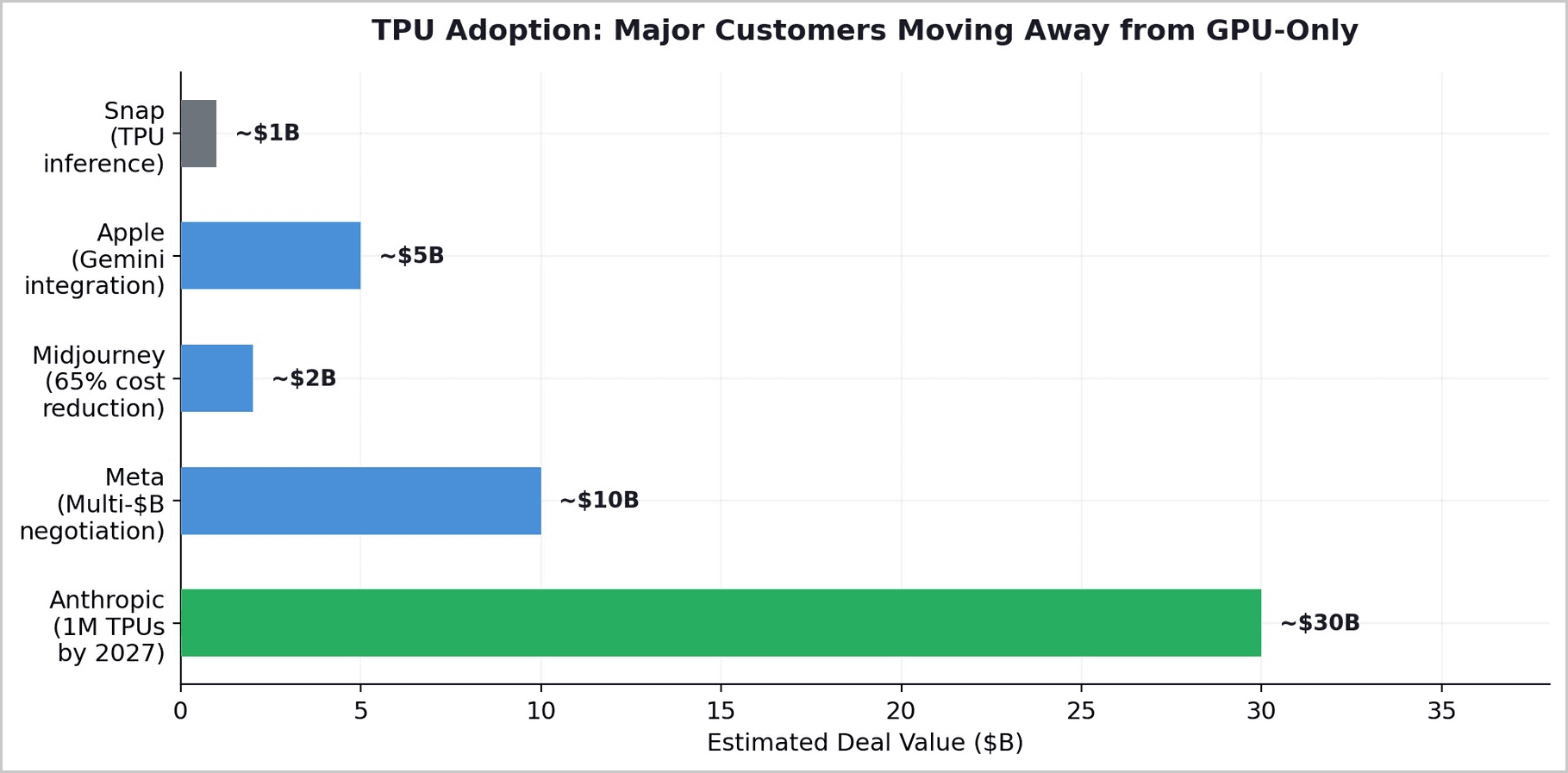
The adoption is no longer theoretical. Anthropic signed the largest TPU deal in Google's history — hundreds of thousands of Trillium chips scaling to one million by 2027. Meta and Google are in advanced discussions for a multi-billion-dollar TPU arrangement. Midjourney reduced inference costs by 65% migrating from GPUs to TPUs. A computer vision startup cut monthly inference bills from $340,000 to $89,000 by switching from 128 H100 GPUs to TPU v6e.
3. Google's Quiet Vertical Integration
The most strategically significant development in the AI hardware landscape is not any single chip or algorithm. It is Google's quiet construction of the only fully vertically integrated AI stack in the world: custom silicon (TPU v6/v7), custom compression (TurboQuant), custom models (Gemini), cloud platform (GCP), and distribution (Search, Android, Chrome, 2.4 billion active users). No other company controls every layer from transistor to end user.
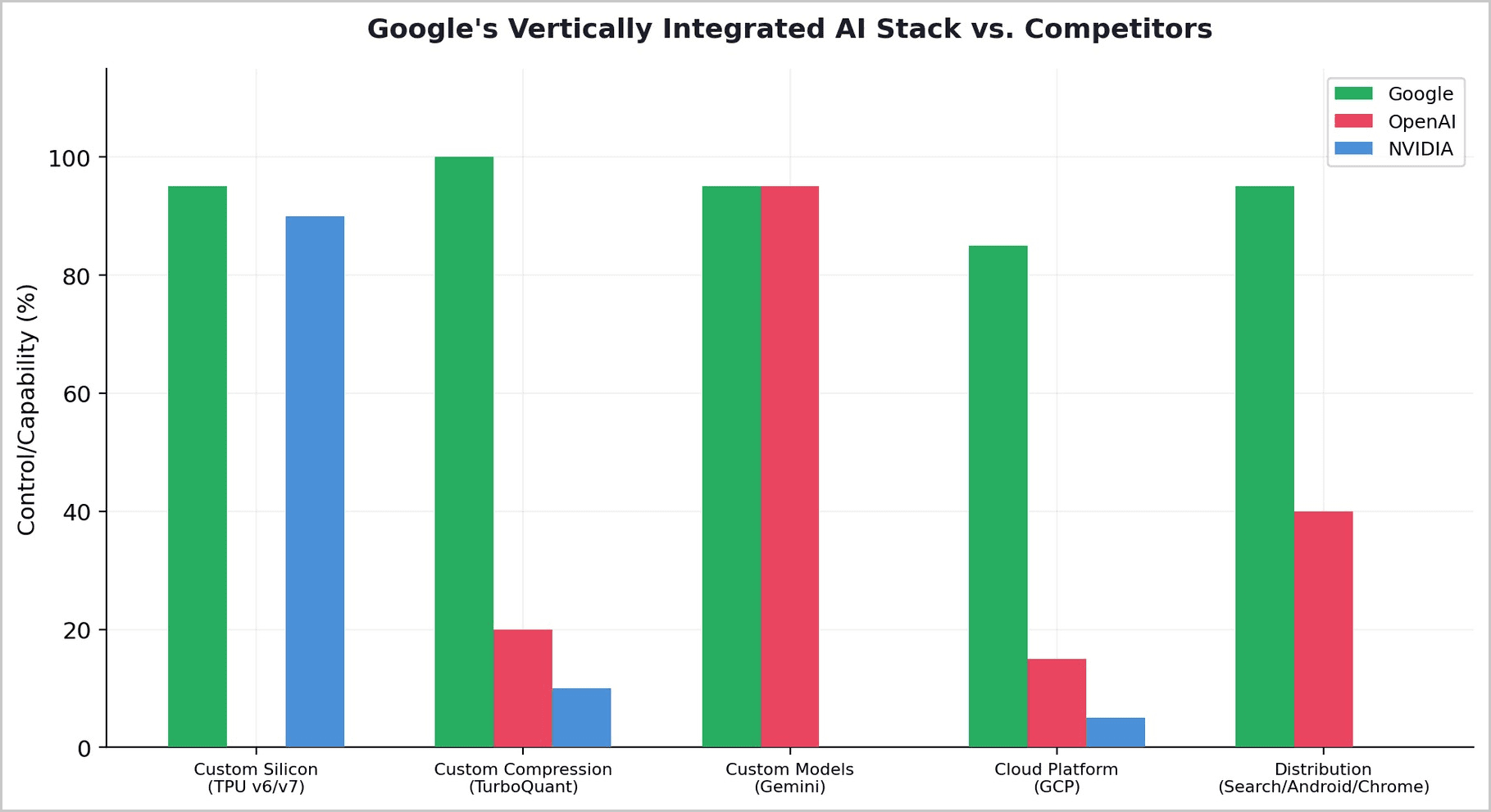
This vertical integration gives Google a structural cost advantage that horizontal competitors cannot match. Google's TPUs eliminate NVIDIA's margin. TurboQuant reduces memory requirements (and HBM vendor leverage). Gemini runs on TPUs natively, not as an afterthought. The entire stack is co-designed for efficiency. NVIDIA charges the "NVIDIA Tax" — a premium that Google, by owning its own silicon, eliminates entirely.
Google published TurboQuant as open research. This was not generosity. It was strategy. Google's Gemini models offer context windows up to 2 million tokens — the most memory-intensive inference scenario possible. For Google to offer million-token contexts at scale without economically untenable costs, it needed exactly the kind of compression TurboQuant provides. TurboQuant weakens NVIDIA's moat (fewer GPUs needed per query) while strengthening Google's (TPU + TurboQuant + Gemini = unmatched cost efficiency for long-context inference).
4. The Value Chain Is Restructuring
The combined effect of TurboQuant, custom silicon, and software optimization is a fundamental restructuring of the AI value chain. Value is migrating from hardware vendors to orchestration layers.
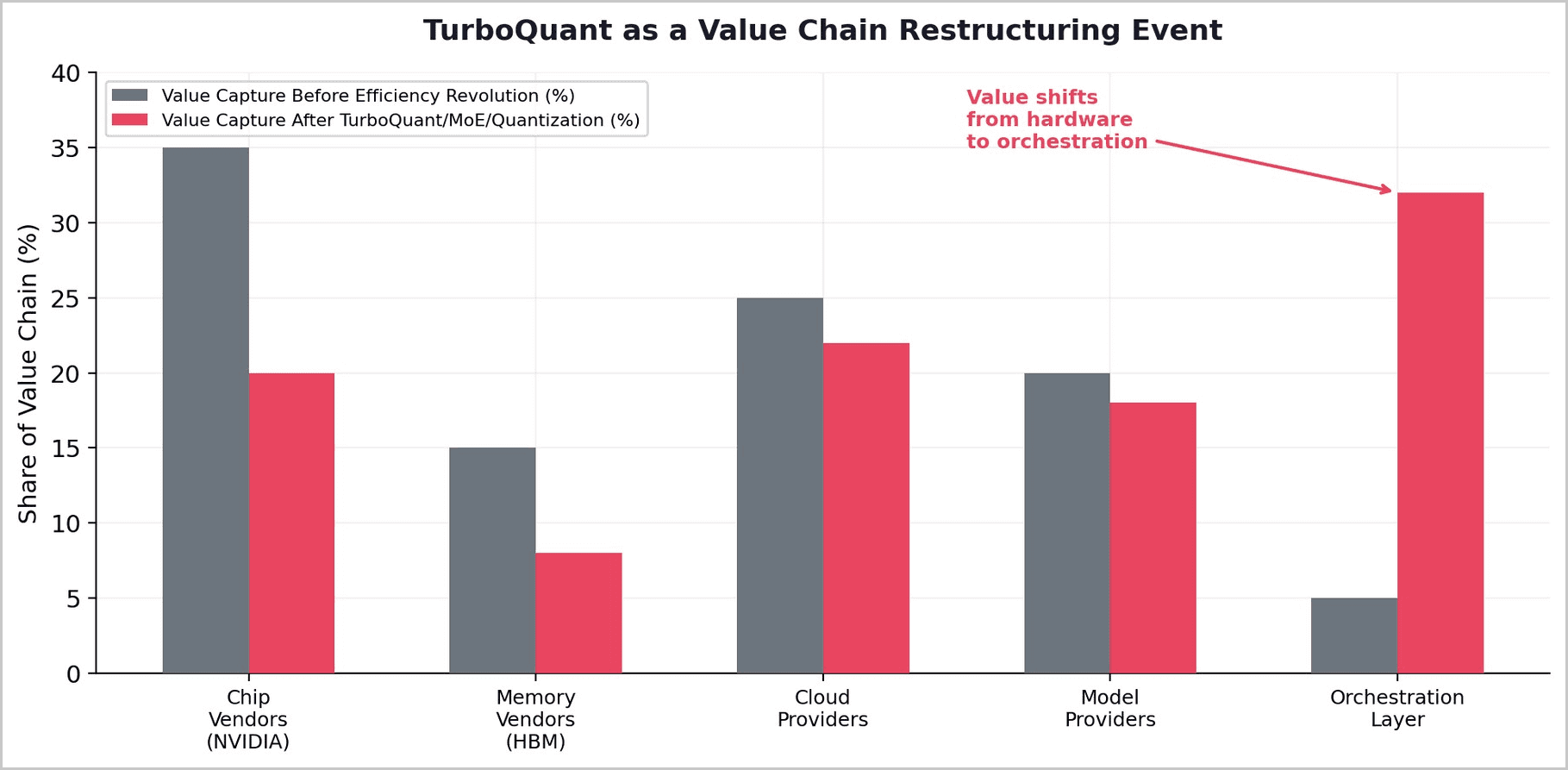
Before the efficiency revolution, hardware scarcity drove pricing power. NVIDIA could charge premium prices because demand exceeded supply. HBM vendors could raise prices 70%+ because memory was the binding constraint. After TurboQuant, MoE, and custom silicon, the binding constraint shifts from "do you have enough hardware?" to "how intelligently do you use the hardware you have?" This is a software question, not a hardware question — and it favors orchestration over accumulation.
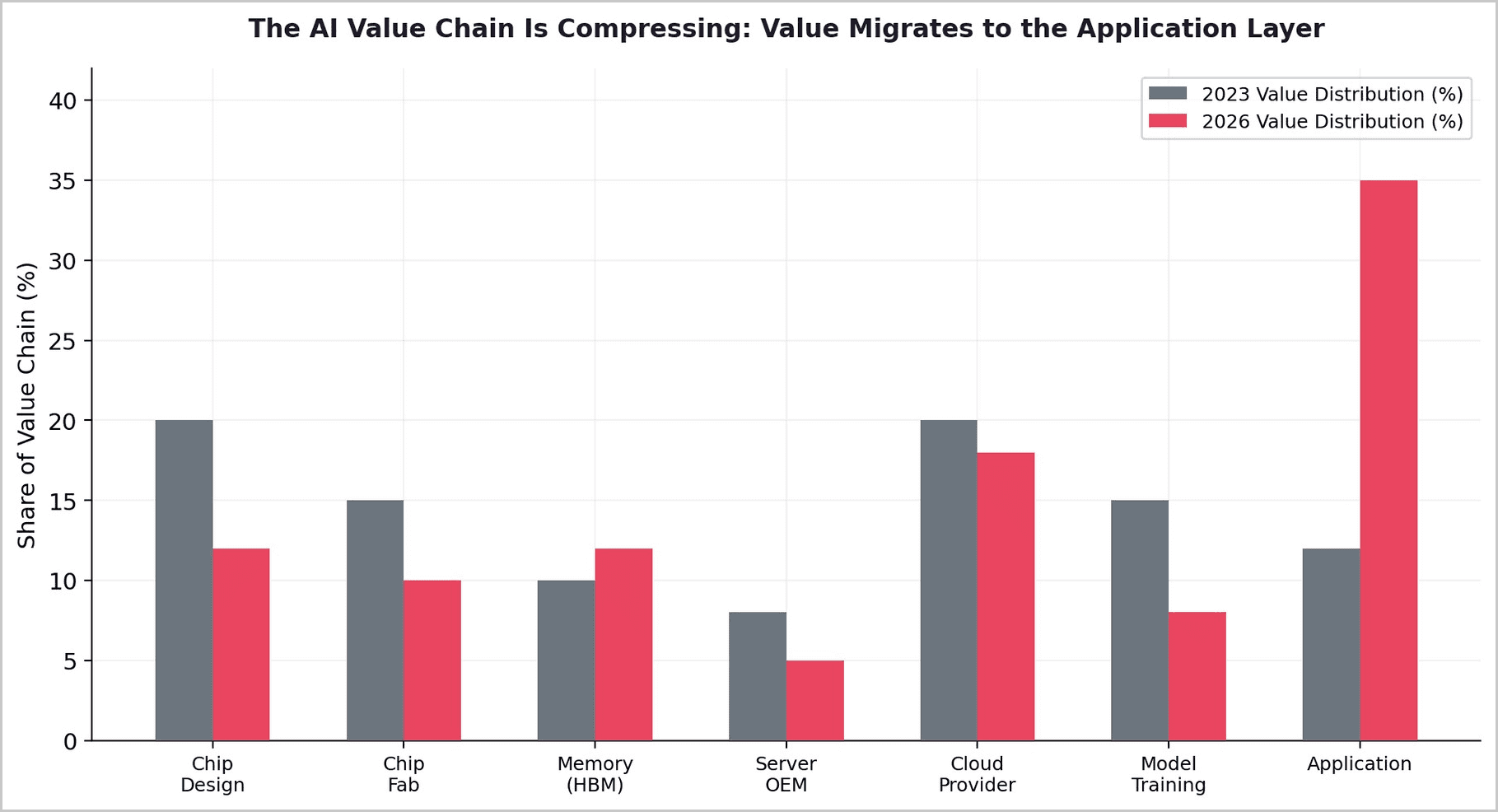
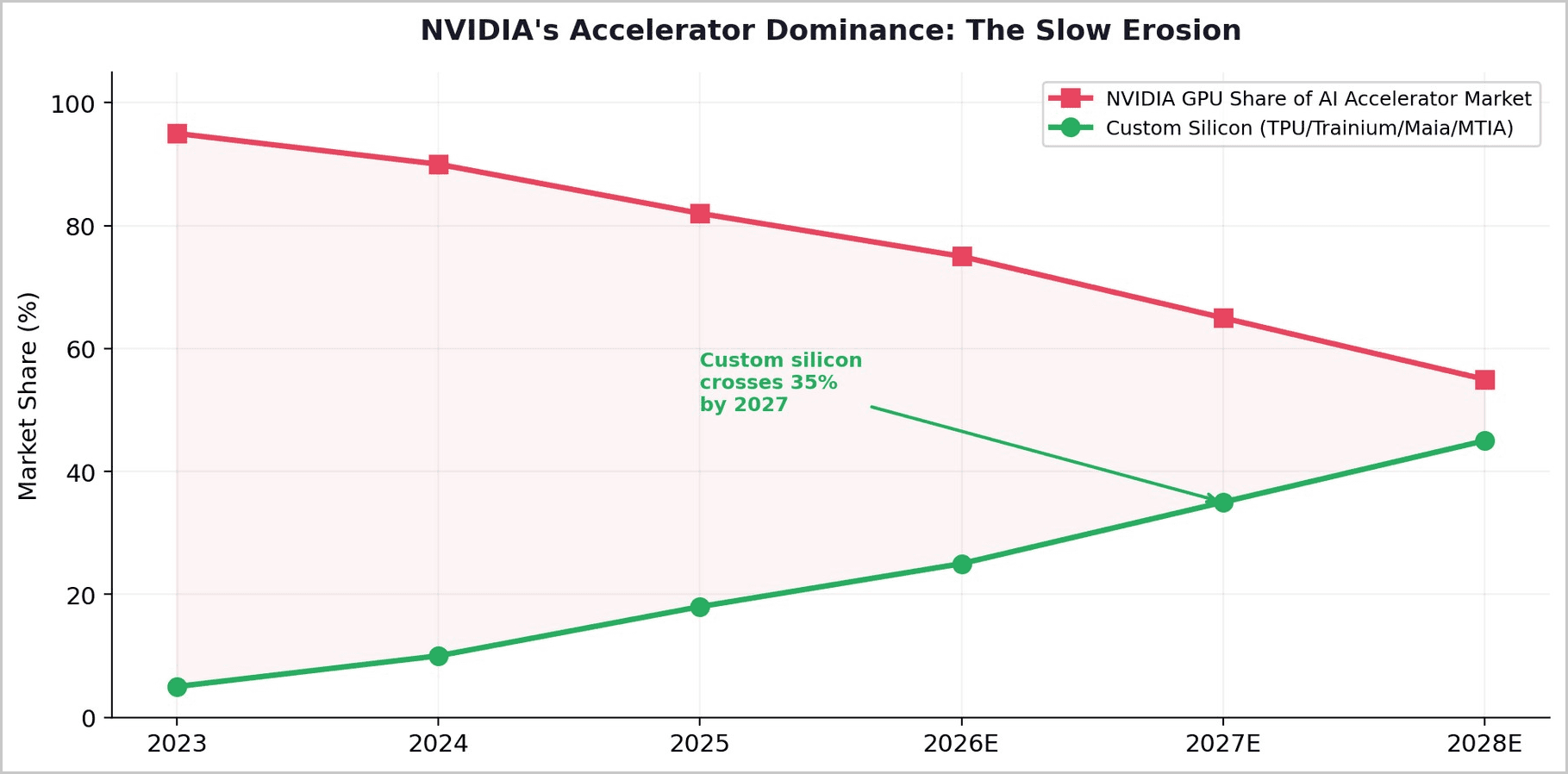
5. The Orchestration Opportunity
If value migrates from hardware to orchestration, the strategic question becomes: who builds the orchestration layer? The answer is not the chip vendors (NVIDIA sells hardware, not intelligence), nor the model providers (they are themselves being commoditized). The answer is whoever can route queries across heterogeneous hardware — GPUs, TPUs, Trainium, Maia — and across multiple models, selecting the optimal combination of chip and model for each task at each moment.
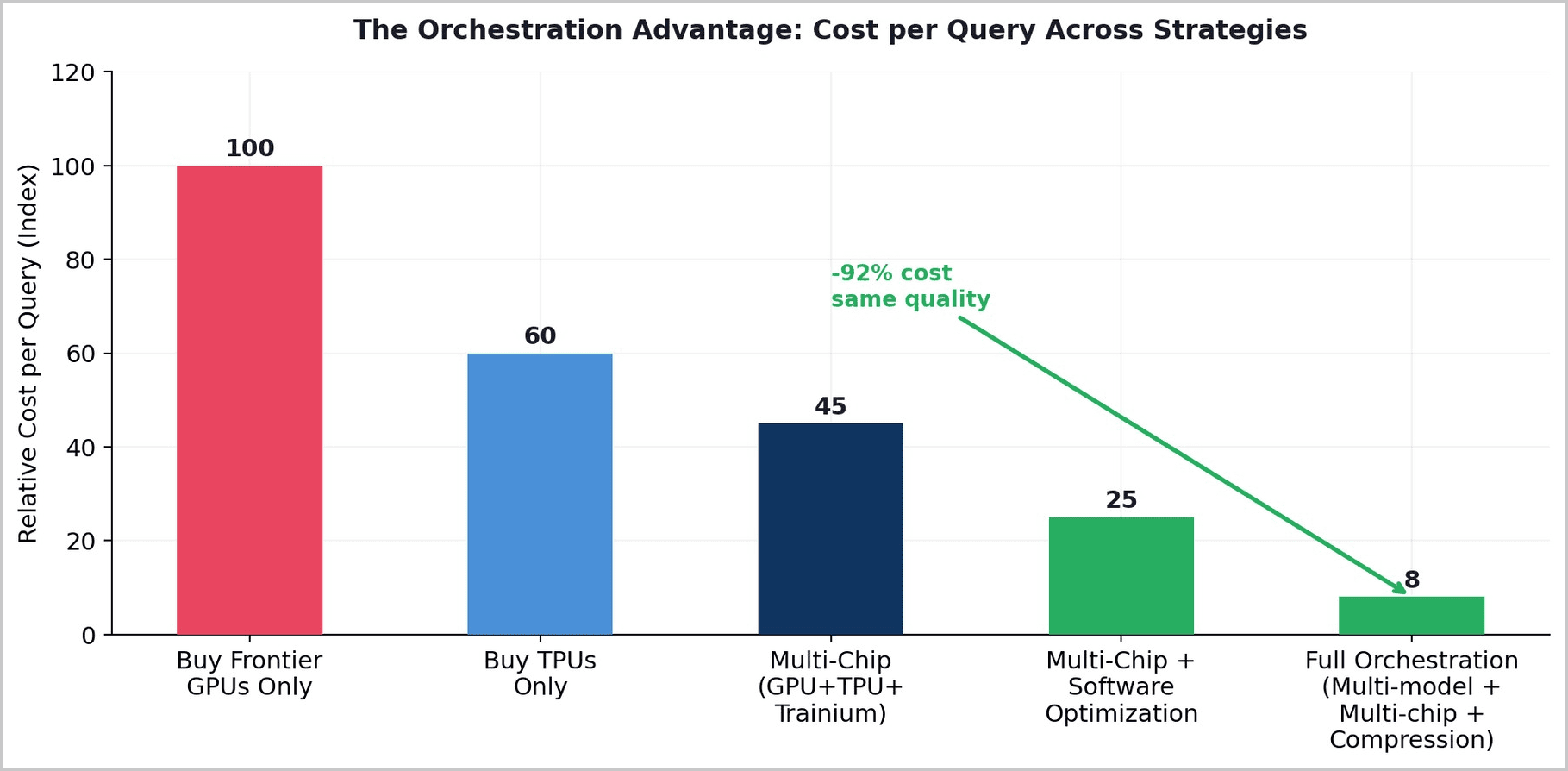
For emerging markets, this restructuring is profoundly enabling. The hardware layer — the most expensive part of the AI stack — is being commoditized by efficiency breakthroughs and custom silicon competition. The orchestration layer — which requires software talent, domain expertise, and local market knowledge — is becoming the primary value driver. A company that can intelligently route queries across the cheapest available hardware, using compressed open-weight models fine-tuned on local data, captures more value per dollar than a company that simply buys more GPUs.
6. Conclusion
TurboQuant is the most important AI paper of 2026, but not for the reason most people think. It is not important because it compresses KV cache 6x. It is important because it accelerates a structural shift in the AI value chain from hardware accumulation to software orchestration.
Memory chip stocks fell the day it was published. NVIDIA rushed a competing 20x algorithm to the same conference. The math lands within 2.7x of the Shannon limit — meaning the easy KV cache gains are mostly spoken for. This is not the beginning of a trend. It is the moment of restructuring — a one-time shift in who captures value in the AI supply chain.
Google understood this and published TurboQuant deliberately — the algorithm weakens NVIDIA while strengthening Google's vertically integrated TPU stack. Anthropic understood this and signed a $30 billion TPU deal. Meta understood this and is negotiating to leave NVIDIA for TPUs. Midjourney understood this and cut inference costs 65% by switching off GPUs. The hyperscalers are becoming their own chip vendors, and the efficiency revolution is making hardware interchangeable.
The winners of this restructuring are not those with the most GPUs. They are those with the most intelligent systems for orchestrating across GPUs, TPUs, Trainium, Maia, and open-weight models — selecting the right chip and the right model for each query at each moment. This is the orchestration layer, and it is the new center of gravity in the AI value chain.
The compression algorithm is the message: hardware is becoming a commodity. Intelligence in how you use it is the moat.
About Redrob Labs:
Redrob (redrob.io) builds large language models and AI tools for the next three billion users. Founded in 2018, the company operates a proprietary multi-model ensemble architecture delivering 90% of frontier performance at 5% of the cost - purpose-built for the unit economics of India and emerging markets. Headquartered in New York with offices in Seoul, New Delhi, and Mumbai. Backed by world-class VC firms. Redrob Labs is the research division of Redrob. Our work is published at redrob.io/research.



