The Jevons Paradox of Intelligence: Why Falling AI Costs Are Making Artificial Intelligence Less Accessible to 85% of the World's Population
Authors:
Felix Kim & Redrob Research Labs
Date:

The global AI industry operates under a foundational assumption: that falling per-token inference costs will inevitably democratize artificial intelligence across the world's population. This paper presents evidence that the opposite is occurring.
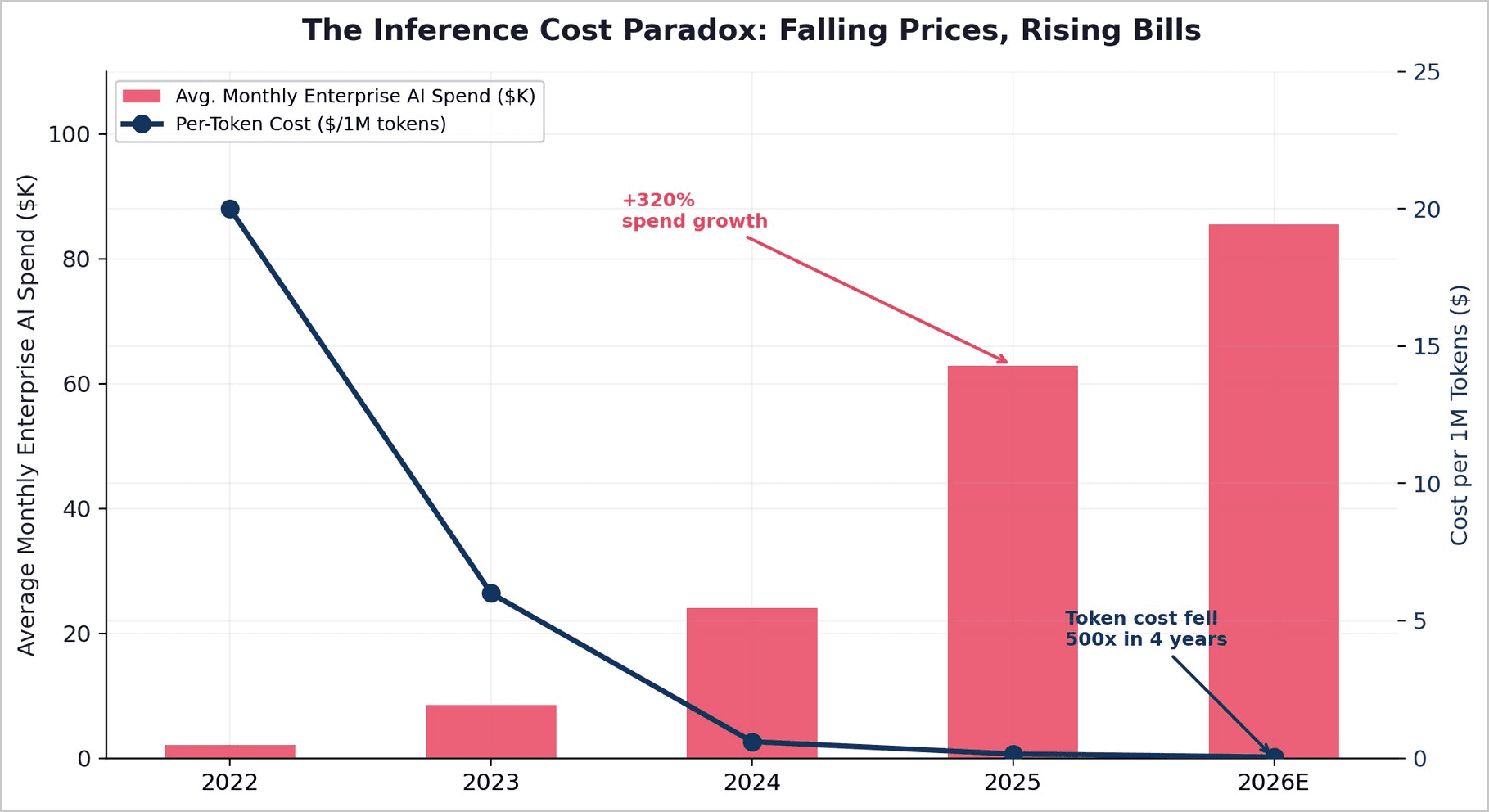
As per-token costs have fallen approximately 500x since 2022, total enterprise AI spending has simultaneously risen over 320%. The shift from simple chat interfaces to agentic, multi-model workflows has multiplied token consumption per task by 15-240x. OpenAI's own inference costs reached $8.4 billion in 2025 and are projected to rise to $14.1 billion in 2026 — growing faster than revenue — while the company's gross margin compressed to just 33%.
These dynamics create an effective cost-of-intelligence floor that structurally excludes markets where users cannot pay more than $0.27-$3.50 per month for digital services. We argue that multi-model ensemble routing architectures — not continued frontier model scaling — represent the only viable path to closing this intelligence divide.
Core Thesis: Per-token AI costs have fallen 500x. Total AI spending has risen 320%. Agentic workflows consume 15-240x more tokens per task. The world’s most-used AI company spends $1.35 for every $1 it earns - on inference alone. For the 5.5 billion people in emerging markets, the net effect is that frontier AI is moving further out of reach, not closer. The only architecture that can profitably serve these users routes 80-95% of queries through lightweight, cost-optimized models, reserving frontier compute for the tasks that truly demand it.
1. The Consensus That Is Wrong
The dominant narrative in AI is one of relentless cost deflation leading inexorably to universal access. Token prices have indeed plummeted — a query that cost $0.03 on GPT-4 in early 2023 can now be served for a fraction of a cent on equivalent-capability models. Gartner projects that by 2030, running inference on a one-trillion-parameter model will cost over 90% less than it did in 2025. API costs across major providers dropped 93% in early 2026 alone.
The data tells a different story. The cost of serving frontier AI per active user is rising, not falling, because the applications users demand consume exponentially more compute than the simple chat interfaces on which price comparisons are benchmarked. The collision between this rising effective cost and the fixed affordability ceilings of emerging markets produces what we term the Intelligence Divide — a gap that widens with every generation of more capable models.
2. The Structural Jevons Paradox in AI
In 1865, William Stanley Jevons observed that improvements to the steam engine — which dramatically reduced coal required per unit of work — ultimately led to a massive increase in total coal consumption. Efficient engines made steam power economical for a far wider range of applications, and demand expanded to overwhelm efficiency gains.
A January 2026 paper by Zhang and Zhang formalized this dynamic for AI as the Structural Jevons Paradox: as the unit price of intelligence falls, downstream firms do not simply run the same workloads more cheaply — they endogenously redesign their agent architectures to consume dramatically more compute.
2.1 Application Complexity Expansion
The most consequential shift in AI deployment between 2024 and 2026 has been the migration from single-turn chat interactions to multi-step agentic workflows. A simple chatbot query consumes roughly 500 tokens. A RAG pipeline consumes 8,000. A code assistant, 15,000. An agentic workflow orchestrating web search, tool use, reasoning chains, and multi-step validation consumes 45,000 tokens or more. Multi-agent orchestration systems can consume upward of 120,000 tokens per task. The price per token fell, but the tokens per task rose 240x.
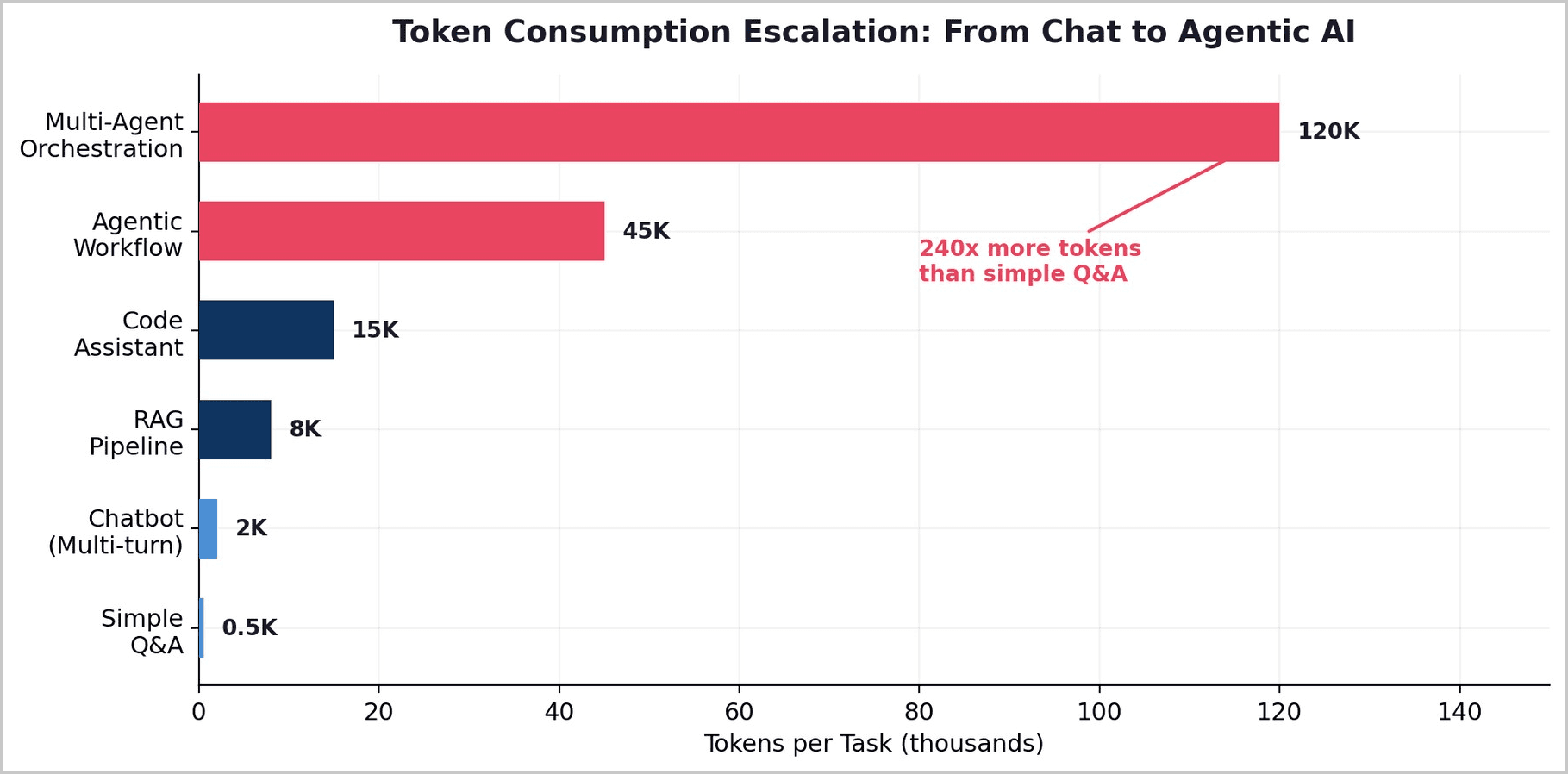
Jensen Huang named this dynamic explicitly at NVIDIA GTC in 2026: the cost per inference token has fallen roughly 50x over two years, while total AI spend is climbing because lower unit costs unlock demand that did not previously exist. Inference now accounts for 85% of total enterprise AI spend, driven by agentic loops consuming 15x more tokens than standard chat.
2.2 The Frontier Cost Escalation
While per-token prices have generally declined, the cost of running frontier-level models has risen approximately exponentially — roughly 18x per year according to a 2026 analysis published on Arxiv. Roughly half of measured progress on benchmarks like GPQA-Diamond is associated with increasing inference spending rather than price-independent technical advances. The models are getting smarter in part because they are thinking harder — running more tokens through more sophisticated reasoning pipelines — not just because the underlying architecture has improved.
2.3 The KV Cache Wall
Beneath the economics lies a physical constraint that no software optimization can fully eliminate. During text generation, the model stores attention key-value pairs for all previous tokens in what is called the KV cache. This cache grows linearly with context length. At 32K context on Llama 3.1 70B, a single user's KV cache consumes approximately 10GB of high-bandwidth memory. At 128K context, it reaches 40GB — half the total memory of an H100 GPU.
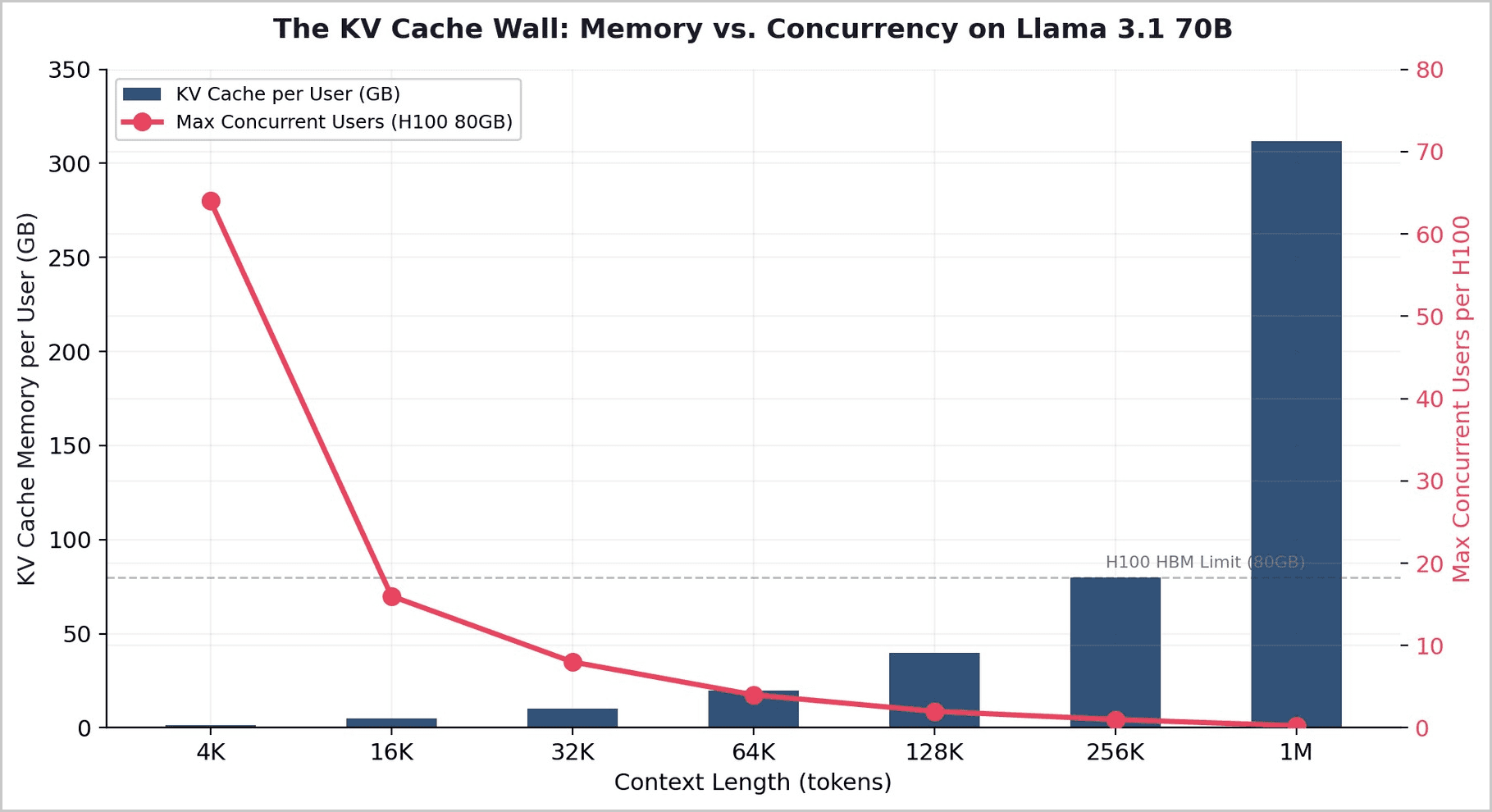
The relationship is linear and non-negotiable: double the context, halve your concurrent users. Google's TurboQuant achieves a 6x reduction. But these improvements are themselves subject to the Jevons Paradox: the memory freed by compression is immediately consumed by longer contexts and more ambitious agentic workflows, not by serving more users at the same context length.
Key insight: TurboQuant does not reduce the cost of AI for end users. It enables longer contexts and more sophisticated workflows for existing users. The efficiency gains flow upward into capability, not outward into accessibility. This is Jevons at the hardware level.
3. The Unit Economics of Frontier AI Are Broken
The most direct evidence that frontier AI cannot be profitably served to mass-market users comes from the financial disclosures of the companies attempting to do so. OpenAI — the world's most widely used AI provider, with 910 million weekly active users and approximately 15 million paying subscribers — posted a 33% gross margin in 2025, constrained by inference costs that reached $8.4 billion and are projected to rise to $14.1 billion in 2026.
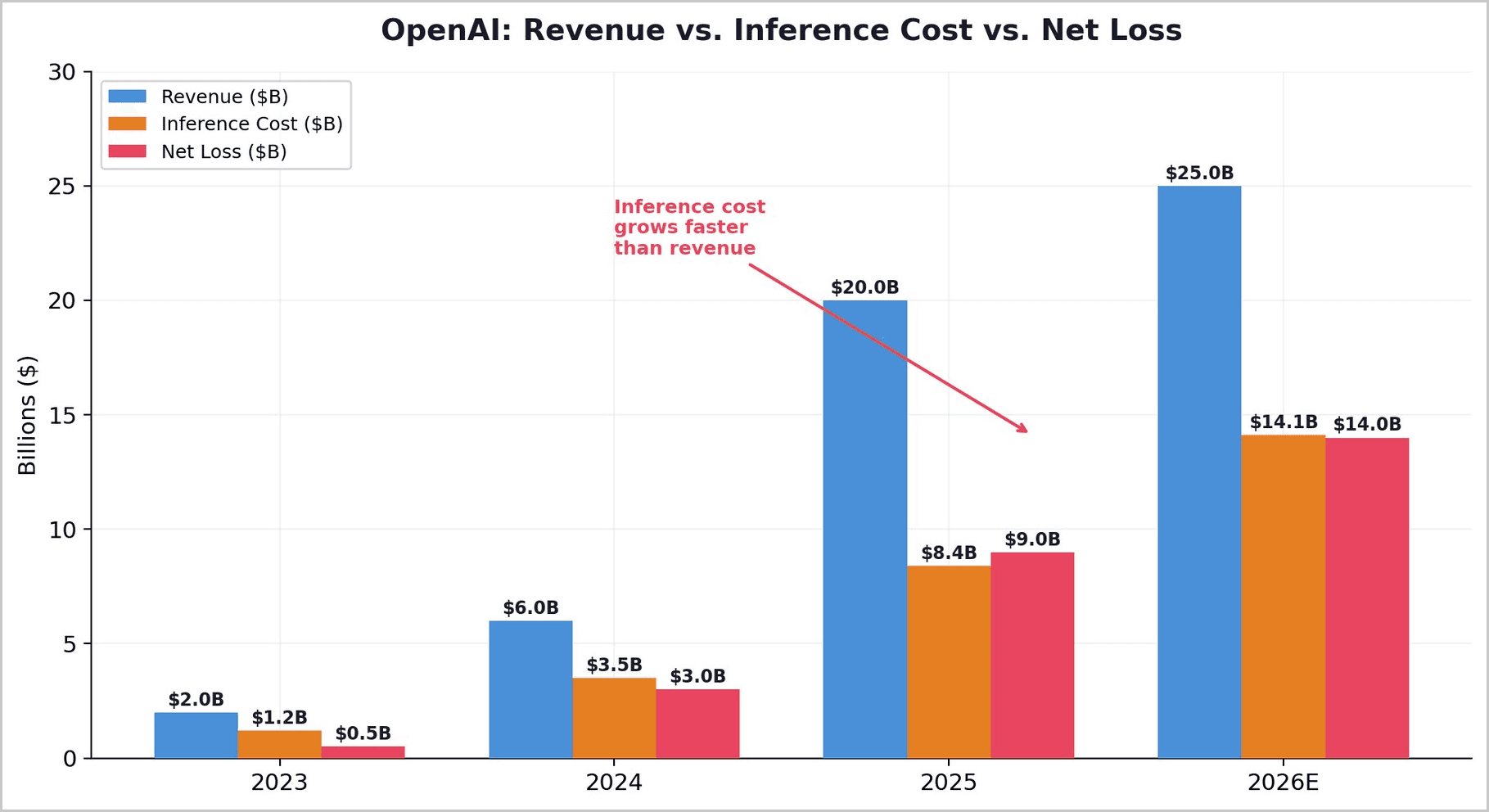
The company's own internal forecasts project $14 billion in losses in 2026 against roughly $25 billion in revenue. Cumulative losses from 2023 through 2028 are expected to reach $44 billion. HSBC analysts concluded that OpenAI faces a $207 billion funding shortfall and will likely not reach profitability before 2030.
OpenAI is not alone. Sam Altman publicly admitted that the company loses money on $200-per-month ChatGPT Pro subscriptions. Anthropic burns 70% of every dollar it earns.
If the world's most well-capitalized AI companies cannot profitably serve paying customers at $20-$200 per month, the idea that these same models will be affordably delivered to users in markets with $2.80 mobile ARPU is not a matter of "give it time" — it is a structural impossibility under the current architectural paradigm.
4. The Intelligence Divide: A Quantitative Assessment
The collision between rising effective AI costs and fixed emerging-market affordability ceilings produces the central finding of this paper. Mobile ARPU — the best available proxy for digital service willingness-to-pay — ranges from approximately $2.8-$3.5 per month in countries like India, Kenya, and Egypt, compared to $22-$48 in advanced economies.
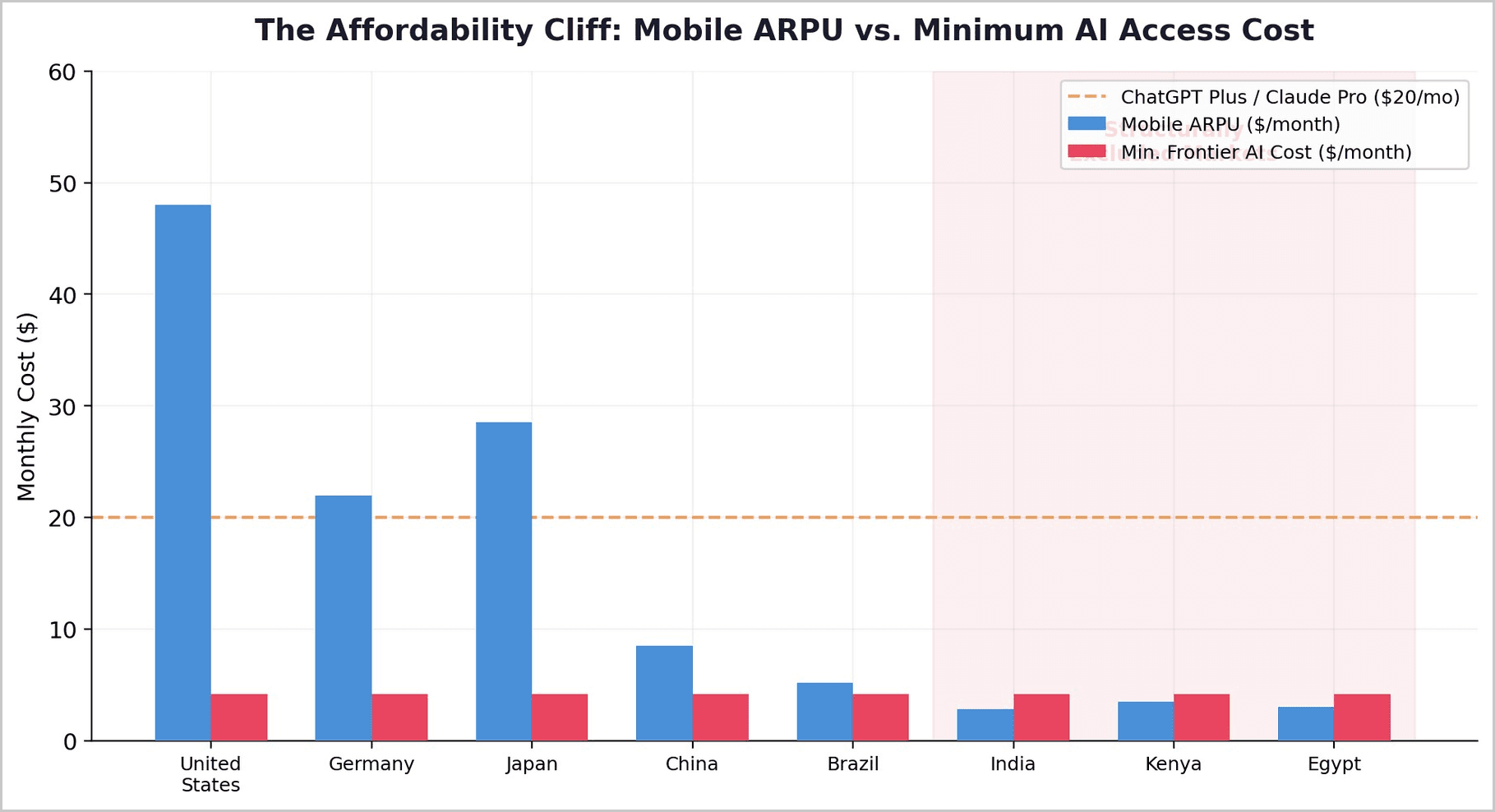
Adding a $20/month AI subscription to the budget of a typical Indian mobile user would more than quadruple their total digital services spending. This is not a price sensitivity issue. It is an affordability physics issue.
4.1 The Diverging Curve
This is not a temporary gap that will close with time. The effective cost to serve frontier AI per active user is rising because applications are becoming more compute-intensive. Emerging-market willingness-to-pay is rising as well, but at a far slower rate. India's GenAI market is projected to reach $6.28 billion by 2030 at a 41.4% CAGR — impressive in isolation, but the gap between what frontier AI costs to deliver and what emerging-market users can afford is widening with each model generation.
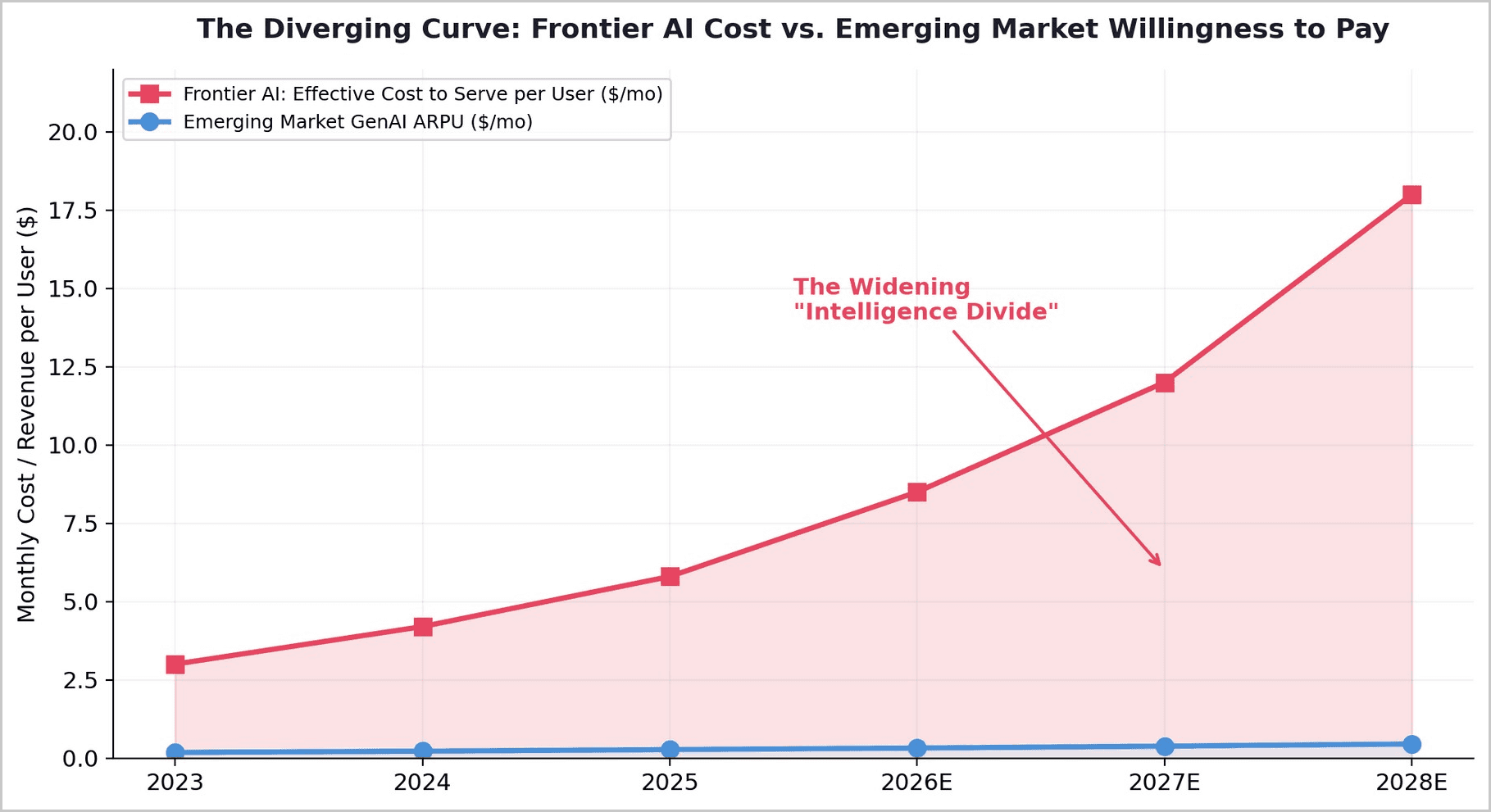
AI providers are aware of this tension. OpenAI, Google, and Perplexity have poured free AI credits into India, sacrificing near-term revenue for market share. But the question everyone is asking is whether India's massive user boom can actually translate into paying customers, or whether companies just burned billions courting users who will never subscribe.
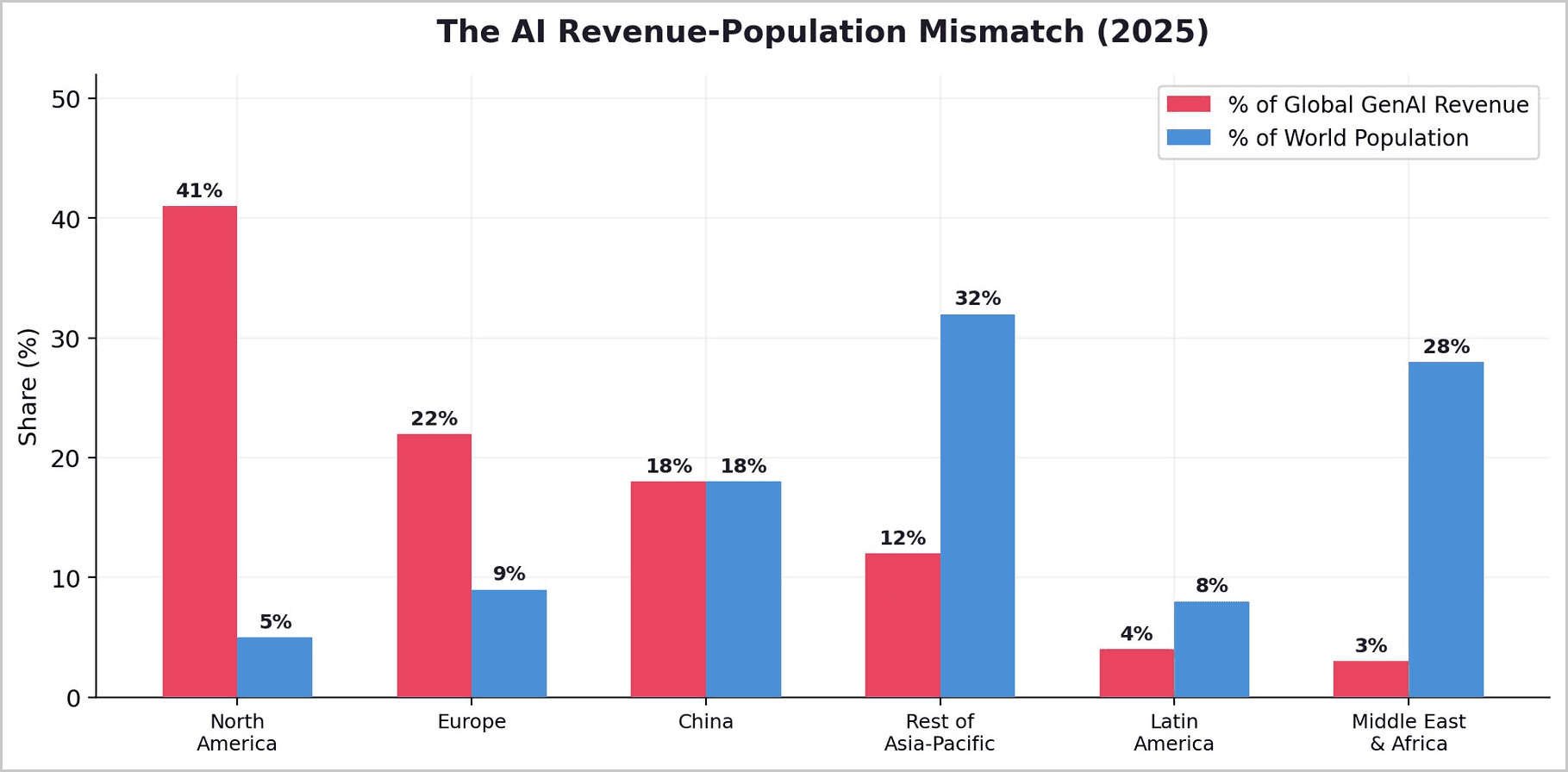
Global GenAI adoption reached just 16.3% of the world's population in the second half of 2025, with advanced economies using AI at nearly twice the pace of developing nations. The pattern is clear: cost is the determining factor.
5. The Architectural Response: Multi-Model Ensemble Routing
If the problem is structural, then the solution must also be structural. The only architecture that can profitably serve emerging-market users at scale is one that fundamentally rethinks how inference is allocated across models.
5.1 The End of the Single-Model Era
The era of single-LLM deployments is over. By 2026, 37% of enterprises are using five or more models in production environments. The companies achieving the best results treat AI model selection like air traffic control — dynamically routing each request to the optimal destination based on complexity, cost, and required quality. The core insight is deceptively simple: for 70-80% of production workloads, mid-tier or lightweight models perform identically to premium frontier models. Only the remaining 20-30% of queries justify frontier compute costs.
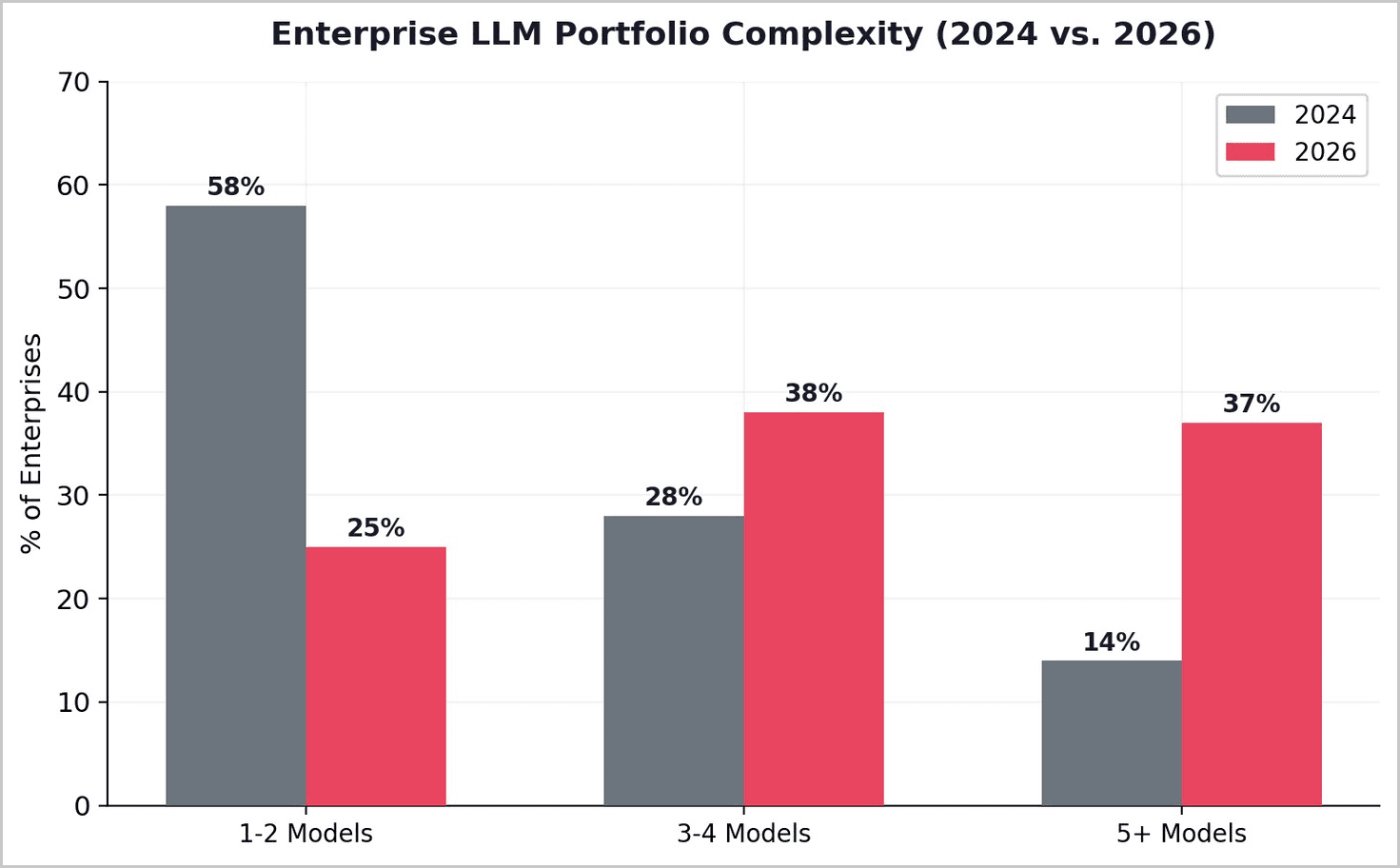
5.2 Quantified Cost Reduction Through Routing
The savings from intelligent routing are not incremental — they are transformative. RouteLLM benchmark data demonstrates 85% cost reduction while maintaining 95% quality on standard benchmarks. Amazon Bedrock's internal testing reports 60% cost savings using Anthropic family routing that matches top-tier quality. Research on consensus-based ensemble approaches shows accuracy gains of 7-15 percentage points over the best single model, with F1-score improvements of up to 65%. On GPQA-Diamond, an ensemble framework raised accuracy from 46.9% to 68.2%, a relative gain exceeding 45%.
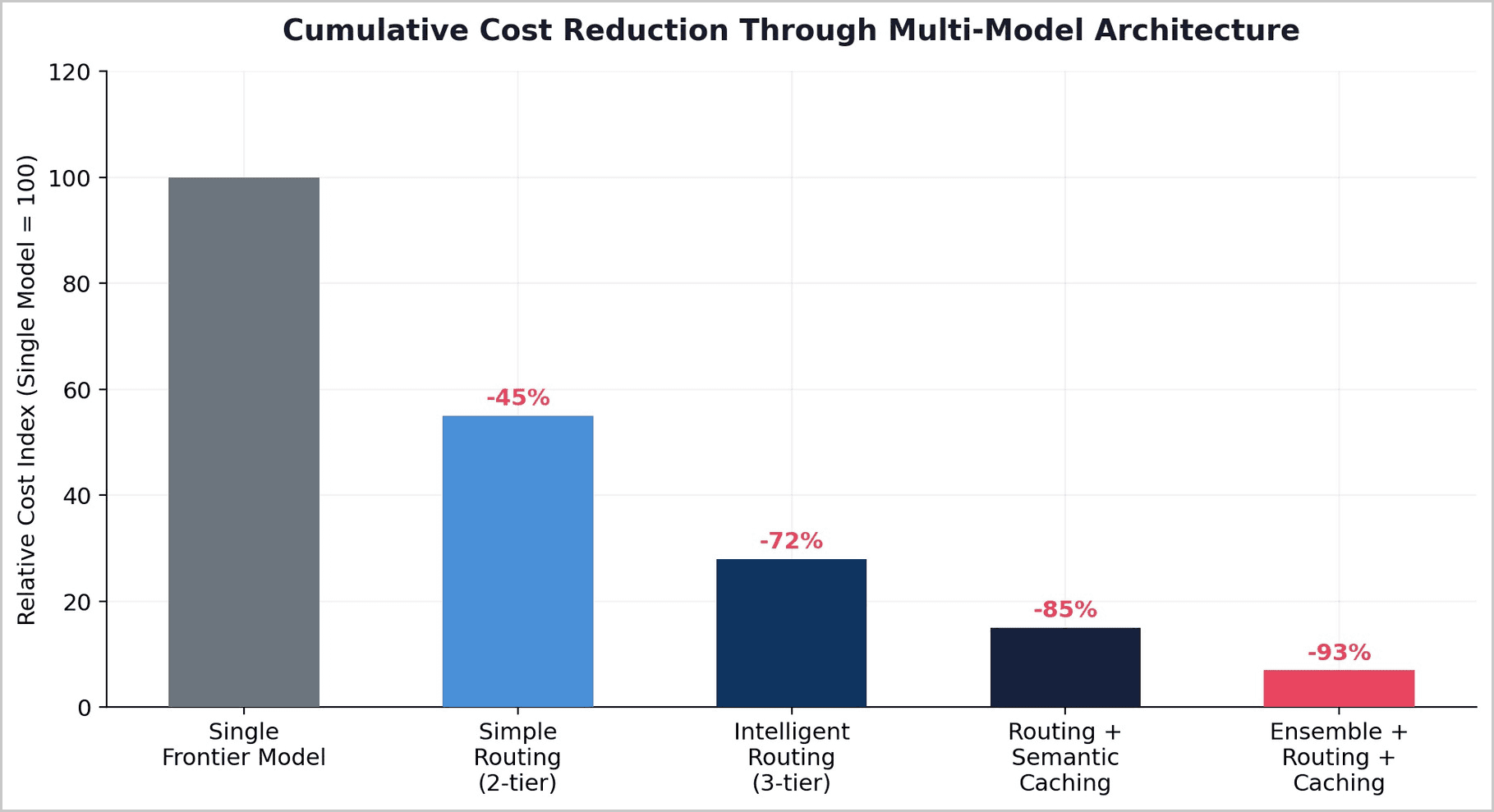
When combined with semantic caching and batch processing optimizations, production systems achieve 47-80% total spend reduction.
5.3 The Ensemble Inversion
There is a deeper, counterintuitive finding in recent routing research that challenges the prevailing "bigger is better" assumption. Studies show that capable routers make pools of weaker models collectively outperform the best single model in that pool by selecting optimally across the query distribution. An ensemble of medium-sized models, intelligently orchestrated, produces more robust results than any single large model.
This finding inverts the scaling hypothesis. The path to both better and cheaper AI does not necessarily run through ever-larger monolithic models. It runs through intelligent orchestration of purpose-fit models — a compositional approach to intelligence that mirrors how biological cognition actually works.
5.4 The Multilingual Dimension
The cost problem is compounded by a linguistic one. Frontier models are overwhelmingly optimized for English. A February 2026 study found that multilingual workloads can cost 2-5x more per semantic unit in non-English languages due to suboptimal tokenization. The ensemble approach naturally accommodates this: a multilingual specialist model handles language-specific queries at a fraction of the cost of routing everything through a general-purpose frontier model.
6. Implications and the Path Forward
6.1 The Subsidization Cliff
Current frontier AI API pricing is subsidized by venture capital and hyperscaler cross-subsidies. This is not a stable equilibrium. OpenAI is spending $1.35 for every dollar it earns. Anthropic burns 70 cents of every dollar. Industry analysts flag inference pricing normalization as the next major enterprise AI budgeting shock, with 30-50% price increases expected within 12-24 months. For emerging-market users, this means the already-unaffordable is likely to become more so.
6.2 The Ensemble Imperative for Emerging Markets
For the next three billion AI users — concentrated in India, Southeast Asia, Sub-Saharan Africa, and Latin America — the path to meaningful AI access does not run through waiting for frontier models to become cheap enough. The Jevons Paradox ensures they will not. The viable path runs through building AI systems architected from the ground up for cost efficiency: lightweight on-device models handling the majority of queries, mid-tier models for moderate complexity, and frontier compute reserved for the genuinely difficult problems.
This is not a compromise architecture. The ensemble routing data demonstrates that this approach delivers equivalent or superior output quality while reducing costs by 85-93%.
6.3 Who Will Serve the Next Three Billion
The companies that will ultimately serve the next three billion AI users are not those building the largest models. They are those building the most intelligent systems for selecting among models — routing the right query to the right model at the right cost, at the scale of billions.
7. Conclusion
The Jevons Paradox of Intelligence is not an edge case or a temporary market condition. It is a structural feature of how the AI industry's economics interact with global income distribution. Every improvement in AI capability increases the compute required per useful outcome. Every reduction in per-token cost is absorbed by more ambitious applications. Every hardware efficiency gain flows into longer contexts and deeper reasoning chains — not into lower prices for end users.
For 85% of the world's population, living in markets where digital service spending is measured in single-digit dollars per month, this dynamic produces an accelerating exclusion from the most transformative technology of the century. OpenAI's own unit economics prove that frontier models cannot be profitably served even to users paying $200 per month. The notion that these same models will reach users at $2.80 ARPU through cost deflation alone is not a timeline question. It is an architectural question.
Multi-model ensemble routing is not merely a cost optimization technique. It is the only architectural paradigm that simultaneously improves output quality and reduces cost to levels compatible with emerging-market economics. The question is not whether ensemble architectures will dominate AI deployment in the developing world. It is which companies will build them first — and whether they will be built by those who understand the markets they serve, or imposed from the outside by companies whose entire cost structure was designed for $48 ARPU.



