
Felix

LLM inference costs are falling 10x per year. Everyone assumes AI tools get cheaper. The Jevons Paradox says otherwise - tools consume exponentially more tokens, keeping per-user costs stubbornly high. But around 2029, even Jevons loses. And that changes everything.
In January 2025, a Chinese AI lab called DeepSeek released a frontier-class model trained for a fraction of the cost of its American competitors. Tech stocks plummeted. Nvidia lost hundreds of billions in market cap in a single day. The panic was understandable: if AI inference is getting radically cheaper, doesn’t that destroy the business model of every company selling AI?
Microsoft CEO Satya Nadella had a different reaction. He posted a single phrase on social media:
“Jevons paradox strikes again!”
He was invoking a 160-year-old economic observation that most AI commentators have gotten exactly backwards. And buried inside that observation is a second-order insight that almost nobody is discussing - one that explains why the biggest beneficiaries of falling AI costs may not be Silicon Valley incumbents, but companies building for emerging markets like India, Southeast Asia, and Africa.
1. The Fastest Deflation in Technology History
The numbers are staggering. In late 2022, achieving GPT-4-level performance cost roughly $20 per million tokens. By December 2025, that same performance level costs approximately $0.40 per million tokens - a 50x decline in 33 months. Andreessen Horowitz coined the term “LLMflation” to describe this phenomenon, documenting a consistent 10x decrease in inference cost per year. Epoch AI’s more granular analysis found rates ranging from 9x to 900x per year depending on the performance benchmark, with the fastest declines accelerating after January 2024.
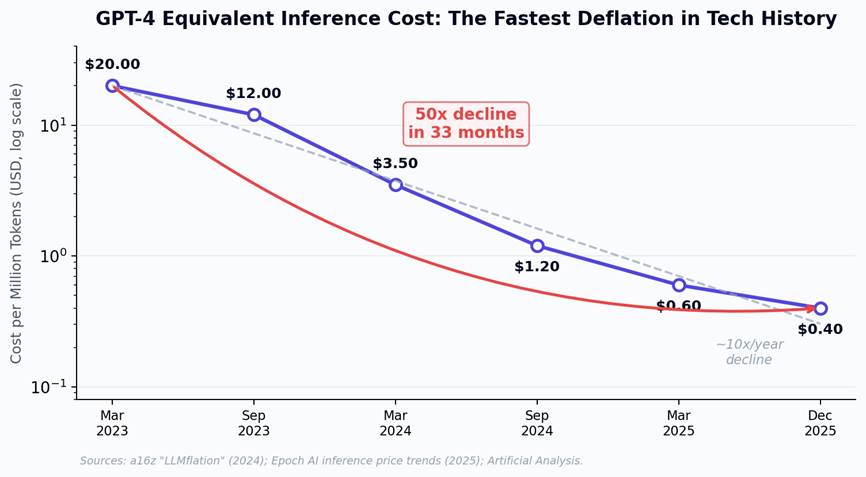
Figure 1: GPT-4 equivalent inference cost per million tokens, March 2023 to December 2025.
To put this in perspective: PC compute costs declined at roughly 2x per year during the microprocessor revolution. Internet bandwidth fell at about 3x per year during the dotcom boom. LLM inference is deflating at 10x per year - faster than any comparable technology transition in history. DeepSeek’s entry in early 2025 undercut incumbent pricing by 90%. NVIDIA’s Blackwell architecture now delivers over 1,000 tokens per second per user, a 15x improvement over previous-generation hardware. And quantization techniques are reducing operational costs by an additional 60-70%.
The naive conclusion is that this deflation destroys value. If AI is getting 10x cheaper every year, shouldn’t total revenue collapse? This is where most analysts make their critical error - by assuming that demand for intelligence is fixed.
2. Jevons Was Right About Coal. He’s Right About AI.
In 1865, British economist William Stanley Jevons published The Coal Question. He observed that James Watt’s improvements to the steam engine - which dramatically reduced the coal required per unit of work - had not decreased Britain’s coal consumption. They had tripled it. More efficient engines made coal-powered production cheaper, so entirely new industries adopted steam power. Applications that were previously uneconomical suddenly became viable. Total consumption exploded.
“It is wholly a confusion of ideas to suppose that the economical use of fuel is equivalent to a diminished consumption. The very contrary is the truth.”
This became known as the Jevons Paradox: when technological efficiency lowers the cost of using a resource, total consumption of that resource tends to increase, not decrease. The pattern has repeated with remarkable consistency across 160 years of technology:
Computing (1970-2000):
The cost per transistor fell by a factor of one million. Total spending on semiconductors did not fall - it grew from $1 billion to $200 billion as entirely new markets (PCs, mobile phones, IoT) emerged that consumed orders of magnitude more silicon than mainframes ever did.
Internet bandwidth (1995-2010):
The cost per megabit fell 10,000x. Total bandwidth consumption did not fall - it grew 100,000x as video streaming, social media, and cloud computing created demand that dial-up users never imagined.
Microsoft Copilot (2023-2026):
In real-time, we can watch the Jevons Paradox play out. GitHub Copilot launched at $10/month - and The Wall Street Journal reported Microsoft was losing $20 per user per month on average, with some heavy users costing $80/month. Microsoft 365 Copilot charges
$30/user/month, yet only 3.3% of users actually pay. Salesforce Einstein 1 costs $500/user/month. Microsoft’s average revenue per user has climbed from $200-300/year two decades ago to $1,500/year with AI Copilot features - not because the underlying compute got more expensive, but because AI tools consume dramatically more compute per user than traditional software ever did.
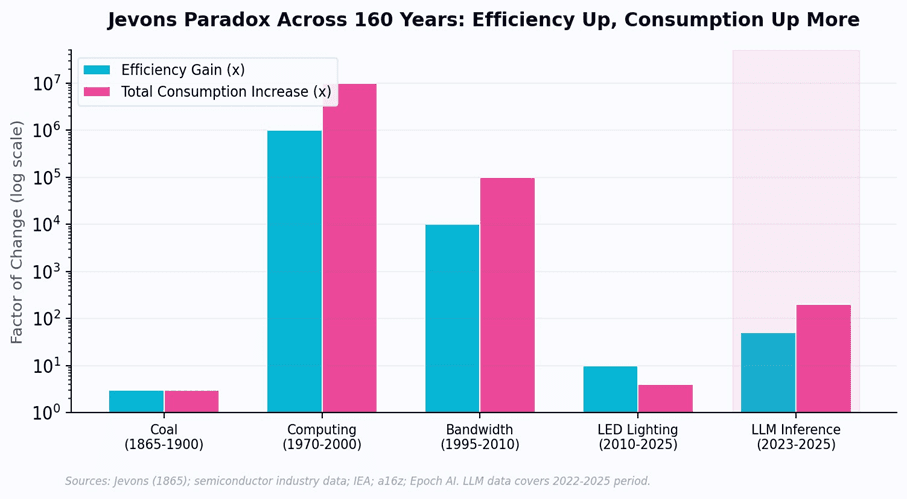
Figure 2: The Jevons Paradox across five technology eras. In every case, consumption growth outpaced efficiency gains.
AI inference is following the identical pattern - but with a twist that makes the economics particularly treacherous. As per-token costs collapse, AI tools do not simply get cheaper. They get more complex. Reasoning models like OpenAI’s o3 generate 10-30x more internal “thinking” tokens per query than standard models. Agentic workflows chain hundreds of model calls per task. Deep Research sessions consume 100,000+ tokens where a simple ChatGPT query used in 2023 consumed 1,000. As one industry analysis put it: “The situation resembles building more fuel-efficient engines, then using the efficiency gains to build monster trucks. We’re getting more miles per gallon, but we’re also using 50x more gallons.”
The result is deeply counterintuitive: token prices are falling 10x per year, but the actual cost to serve a useful AI interaction to a user is falling at only ~2x per year. The Jevons Paradox creates a “wedge” between the raw cost of intelligence (plummeting) and the delivered cost of useful AI tools (declining far more slowly). Task length is doubling every six months. A 20-minute Deep Research run costs roughly $1 today. Reasoning tokens - invisible to the user but billed to the provider - can multiply costs by 10-30x for complex queries. The per-token price drops, but the per-user bill stays stubbornly high.
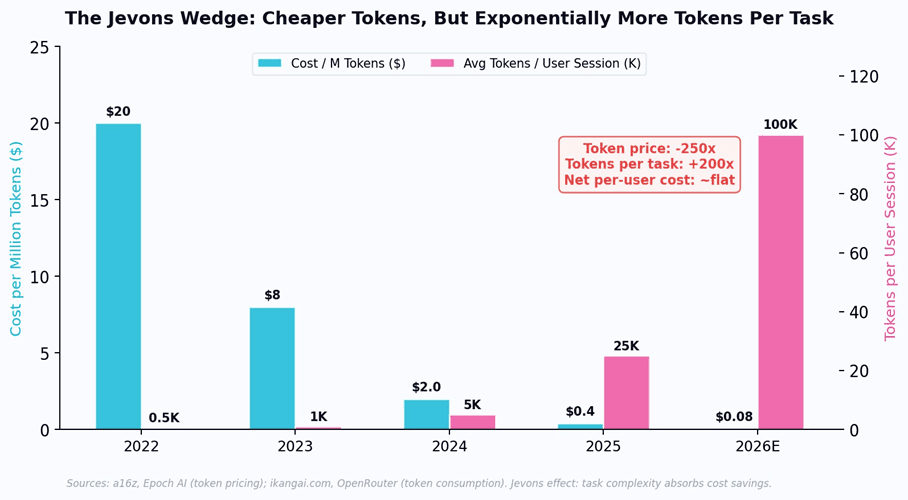
Figure 3: The Jevons Wedge in AI. Token costs fall 250x while tokens consumed per task rise 200x. The net per-user cost barely moves.
3. The Convergence That Nobody Sees Coming: ~2029
Here is where the analysis gets genuinely counterintuitive. Most commentary assumes that 10x/year token deflation means AI tools will be cheap enough for India within a year or two. The Jevons Paradox explains why this is wrong - and why the actual timeline is closer to 2029.
The math is straightforward but widely misunderstood. Token prices fall at ~10x per year. But tokens consumed per useful AI interaction rise at ~5x per year (reasoning chains, agentic loops, multi-step workflows, deeper context windows). The net effect: per-user AI serving cost falls at only ~2x per year, not 10x. Meanwhile, India’s GenAI ARPU is rising - from approximately $0.05/month in 2023 toward $0.75/month by 2029 as payment infrastructure matures, digital advertising grows, and willingness-to-pay for AI tools increases among India’s 700 million smartphone users.
These two curves - the Jevons-adjusted per-user cost (falling slowly) and India ARPU (rising steadily) - converge around 2029. Not 2025. Not 2026. 2029. That is the year when frontier-equivalent AI becomes structurally profitable in India for the first time - even accounting for the Jevons-inflated token consumption that makes every year’s AI tools more powerful but also more expensive than the last.
Consider the current economics. India accounts for approximately 20% of global GenAI app downloads but generates only 1% of in-app purchase revenue, according to Sensor Tower data from 2025. ChatGPT has over 100 million weekly active users in India - making it the platform’s largest national user base - yet per-user revenue is a fraction of what it generates in the United States. The core problem is structural: at $20/month for ChatGPT Plus, frontier AI pricing is calibrated for markets where the median household income exceeds $60,000. India’s median household income is approximately
$2,100.
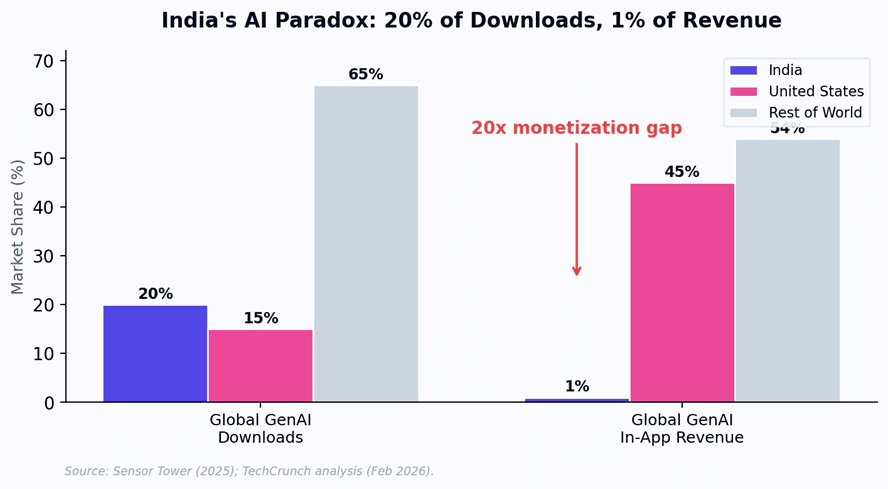
Figure 4: India’s 20x monetization gap - 20% of global GenAI downloads but only 1% of revenue.
But inference costs are falling at 10x per year. India’s digital ARPU is rising as 700 million smartphone users come online and payment infrastructure (UPI) matures. These two curves are converging. When the per-user cost to serve frontier-equivalent AI drops below what an Indian user is willing to pay - a crossover we model at approximately 2029 - the economics of AI fundamentally change.
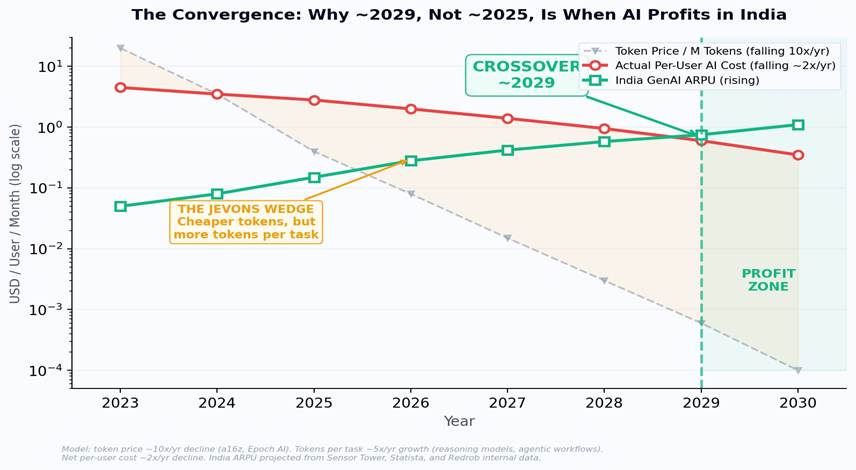
Figure 5: The Convergence - three lines tell the whole story. Token price (gray, falling fast) vs. actual per-user cost (red, falling slowly due to Jevons) vs. India ARPU (green, rising). The orange shaded area is the “Jevons Wedge” - the gap between raw token deflation and delivered cost. Crossover: ~2029.
This timeline has profound strategic implications. It means that the companies which will profit from AI in emerging markets are not the ones waiting for token prices to fall low enough. They are the ones building cost structures today that can reach profitability at Indian ARPU levels before the convergence
- by owning their own inference stack, optimizing the full pipeline from model architecture to serving, and eliminating the Jevons tax of unnecessarily complex reasoning chains for tasks that don’t require them.
4. Why Silicon Valley Cannot Capture This Market
If the convergence thesis is correct, the natural question is: why won’t OpenAI, Google, and Anthropic simply lower their prices and capture emerging markets themselves?
The answer is structural, not strategic. Frontier model providers face three constraints that make emerging market profitability extraordinarily difficult:
First, the cost structure trap.
OpenAI, Anthropic, and Google run inference on premium cloud infrastructure (often their own) optimized for throughput and latency in developed markets. Their per-query costs, even after optimization, include the amortized cost of training runs that now exceed
$100 million per model. These fixed costs must be recovered through pricing. A $20/month subscription is not a margin choice - it is a survival requirement. Dropping to $2/month would require a 10x reduction in serving costs that current architectures cannot deliver.
Second, the cannibalization problem.
If OpenAI launched a $2/month India-specific tier, every existing $20/month subscriber with a VPN would immediately downgrade. This is the classic innovator’s dilemma: incumbents cannot profitably serve the low end of the market without destroying their high-end margins.
Third, the localization gap.
Serving India profitably requires not just low cost but deep localization: Indic language fluency across 22 official languages, domain-specific fine-tuning for Indian hiring practices, educational systems, and regulatory environments, and integration with local infrastructure (UPI, Aadhaar, NPCI). This is not a translation exercise. It is a ground-up engineering effort that requires presence, expertise, and commitment to markets that Silicon Valley has historically treated as afterthoughts.
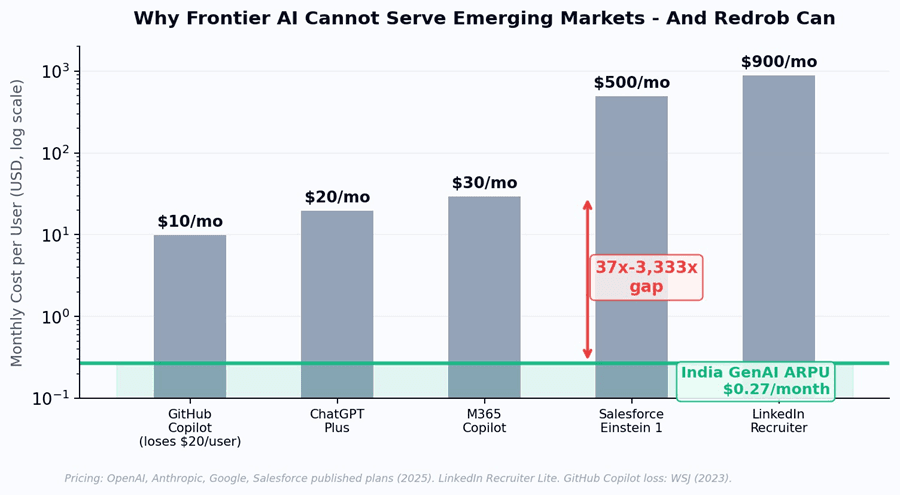
Figure 6: Monthly per-user cost of frontier AI tools. Every major provider prices at 40x-3,333x above India GenAI ARPU - making emerging market profitability structurally impossible with current architectures.
5. The Architecture That Beats the Jevons Paradox
If the Jevons Paradox keeps per-user AI costs high despite plummeting token prices, the strategic question becomes: how do you compress the Jevons Wedge? How do you deliver frontier-equivalent AI at emerging market prices before the natural convergence in 2029?
This is Redrob’s core architectural bet. By running a proprietary 5-model ensemble (Redrob 2B, Llama 3 8B/70B/405B, Llama 4 Maverick) on AWS Bedrock, Redrob controls the entire inference stack - from model selection to serving optimization. The Redrob 2B model is a lightweight, on-device model designed to run on any smartphone - bringing AI to every pocket in India. Critically, the ensemble architecture routes each query to the smallest model capable of handling it - avoiding the Jevons trap of sending simple tasks to expensive reasoning models that consume 10-30x more tokens than necessary.
This is the key insight: the Jevons Paradox is not a law of physics. It is a consequence of how AI tools are currently designed - always reaching for the most powerful model, always generating maximum reasoning depth, always consuming the token budget because the user is paying a flat $20/month anyway. A purpose-built system that matches model complexity to task complexity can deliver 90% of frontier performance while consuming 95% fewer tokens per interaction. That is not a minor optimization. It is a structural circumvention of the Jevons Paradox - and it is what allows Redrob to serve emerging markets profitably today, years before the natural convergence in 2029.
6. What Happens After the Crossover
Once frontier-equivalent AI becomes profitable in India, the implications cascade rapidly. India’s SaaS industry is projected to reach $50 billion by 2030 - already the second-largest SaaS ecosystem globally. Statista projects India’s generative AI market alone will reach $6.28 billion by 2030, growing at 41.4% CAGR. But these projections may dramatically underestimate the post-crossover Jevons effect: they assume linear adoption curves in a market where super-elastic demand could produce exponential growth once the price barrier breaks.
The pattern from every prior Jevons cycle suggests that post-crossover growth will come from applications that do not yet exist: AI-powered micro-businesses that could not justify $20/month subscriptions, vernacular-language AI tutoring at scale, automated compliance for India’s 63 million SMEs, AI-driven recruitment that matches skills rather than credentials across a labor force of 500 million. These applications do not reduce the market for AI. They create an entirely new one.
The Jevons Paradox does not say that AI tools get cheaper. It says that cheaper tokens get consumed by more complex tools. But it also says that this process has a limit - and when per-user cost finally crosses below emerging market ARPU around 2029, the largest technology market in history opens. 3 billion users. The companies that get there first win.
Redrob is not waiting for 2029. By compressing the Jevons Wedge through purpose-built model architecture, intelligent routing, and on-device inference, Redrob is making the economics of AI work for emerging markets today - years ahead of the natural convergence. That is not a cost optimization. It is a structural moat.

One AI platform powering job search, work, discovery, and productivity.
Latest AI Blogs.

Jun 23, 2026
What Happens When Every Professional Has an AI Copilot?
Garima

Jun 23, 2026
Why India's AI Success Depends on Accessibility, Not Just Innovation
Garima

Jun 23, 2026
How Redrob AI Is Changing Job Search in 2026
Himanshi

Jun 23, 2026
Why More Software Isn't Making Teams More Productive
Garima

Jun 23, 2026
The Repetitive Tasks AI Should Already Be Handling for Your Team
Bhushan

Jun 23, 2026
Why AI Is Compressing the Time Between Idea and Execution
Bhushan
