Llama Made Intelligence Free. It Did Not Make Intelligence Accessible

FELIX

Llama 4 Maverick is free, open source, and frontier-class. Anyone can download it. But “anyone can download a model” is like saying “anyone can download Linux.” True - and it took Red Hat and AWS to turn Linux into products the world actually uses.
Meta’s Llama 4 Maverick is one of the most important contributions to AI in the last decade. By releasing a frontier-class model as open source, Meta has permanently lowered the floor for AI research and development worldwide. 400 billion parameters. Mixture-of-experts efficiency. Performance competitive with GPT-4o. A million-token context window. Free to download, modify, and deploy. This is a genuine gift to the global AI ecosystem.
And yet. MIT research documents that 95% of generative AI pilots fail to reach production. Despite being free, Llama holds just 9% of enterprise AI market share, according to Menlo Ventures - behind Anthropic (32%), OpenAI (25%), and Google (20%). One enterprise respondent put it plainly: “100% of our production workloads run on closed-source models. We started with Llama for POCs, but couldn’t keep up with the performance of closed-source over time.”
How can the best free model in history have only 9% market share? Because this narrative confuses two fundamentally different things: the cost of intelligence and the cost of making intelligence accessible. They are not the same. And the gap between them is where the next hundred-billion-dollar companies will be built.
1. Linux Was Free. Red Hat Was Worth $34 Billion.
In 1991, Linus Torvalds released the Linux kernel as free, open source software. Anyone could download it, modify it, and deploy it. The conventional wisdom predicted that Linux would destroy the commercial operating system market. Free software would replace paid software. End of story.
What actually happened was more interesting. Linux became the dominant server operating system - but the value did not accrue to the open source project. It accrued to the companies that built the distribution layer on top. Red Hat packaged Linux with enterprise support, security patches, and certification - and sold for $34 billion to IBM. AWS ran Linux in the cloud and became a $100 billion
ARR business. Canonical built Ubuntu and captured the developer market. The Linux kernel generated
$0 in revenue. The companies that distributed Linux generated hundreds of billions.
The pattern repeats across every era of open technology. Wikipedia made knowledge free - Google captured $300 billion per year by distributing it through search and personalization. Android (AOSP) was open source - Google and Samsung captured $270 billion+ by building the Play Store, Google Mobile Services, and hardware distribution. OpenStreetMap made maps free - Uber and Grab built
$190 billion of combined value by using those maps to distribute ride-hailing services.
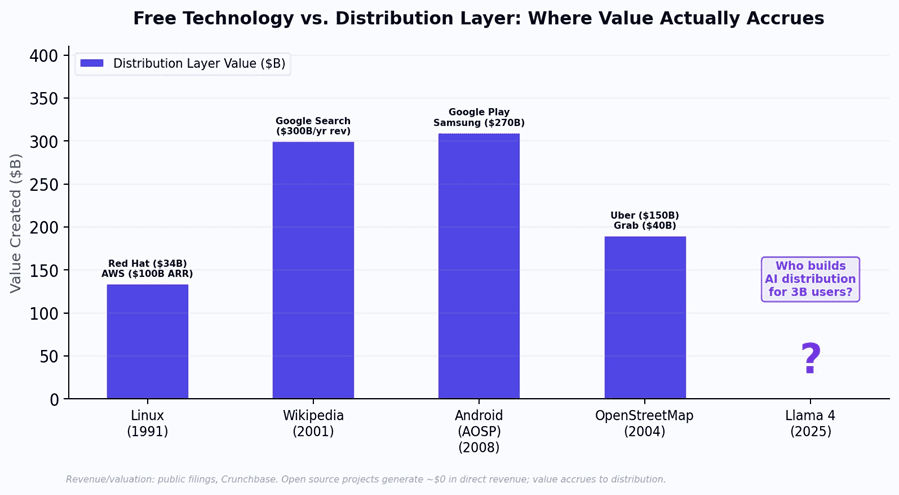
Figure 1: In every era of open technology, the distribution layer captures 100-1000x more value than the open source project itself. AI will follow the same pattern.
Llama 4 Maverick is AI’s Linux moment. The model is free. The intelligence is commoditized. The question is no longer “who builds the best model?” It is “who builds the distribution layer that makes this intelligence accessible to 3 billion people?”
2. “Free” Costs $8,700 Per Month: The Serving Economics
When the first Model T rolled off Ford’s assembly line in 1908, it was revolutionary - but it was useless without roads, gas stations, mechanics, and traffic laws. The car was the technology. The distribution infrastructure was everything else. Llama 4 faces the same problem. The model is free. Running it is not.
Llama 4 Maverick requires a minimum of 2x NVIDIA H100 NVL GPUs for stable production deployment. Self-hosting on 4x A100s costs approximately $8,700 per month - before a single user sends a single query. This only breaks even against API access at roughly 30 million users per month, a scale that fewer than 20 AI companies globally have achieved. For a startup trying to serve India, “free model” still means five-figure monthly infrastructure bills on day one.
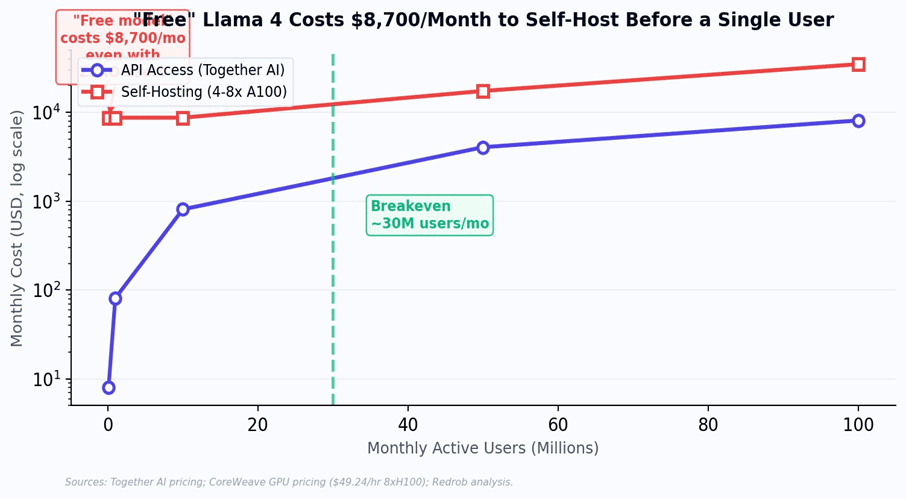
Figure 2: The 'free model' paradox. Self-hosting Llama 4 costs $8,700/month at minimum, regardless of user count. The model is free; the compute to run it is not.
Meta estimates Maverick inference at $0.19-0.49 per million tokens with optimized distributed inference. But this assumes GPU infrastructure that most emerging market companies do not have. India’s subsidized compute under the IndiaAI Mission provides 4,096 H100 GPUs total - for the entire country. The gap between “free model” and “free to serve” is a chasm, and it is denominated in GPU-hours.
3. The Integration Tax: Wikipedia Did Not Replace Google
Wikipedia contains more factual knowledge than any encyclopedia in history, and it is entirely free. Yet Google generates $300 billion per year in revenue. Why? Because raw knowledge and accessible knowledge are different products. Google added search, ranking, personalization, advertising, mobile apps, voice search, and an ecosystem of integrations that turned static knowledge into a dynamic, personalized experience. Wikipedia provided the content. Google built the distribution.
The same integration tax applies to Llama. Downloading the model is 1% of the work. The other 99% is what separates a prototype from a product - and it is why 95% of GenAI pilots never reach production. Enterprise surveys show 37% of organizations spend over $250,000 per year on LLM deployment, and 73% spend over $50,000 - none of which goes to model licensing, since the model is free. It goes to everything above the model: prompt engineering, RAG pipelines, guardrails, domain fine-tuning, voice interfaces, auth, billing, monitoring, and the hardest part - iterating with real users to build something they actually need.
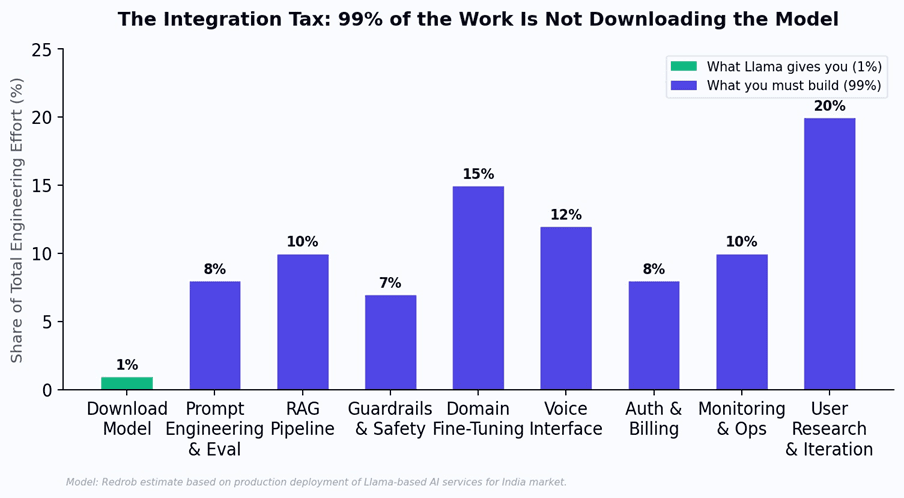
Figure 3: The integration tax. Downloading the model is 1% of total engineering effort. The other 99% is what separates a model from a product.
4.The Real Cost: Model vs. Full Stack for India
When Edison invented the light bulb, he immediately realized the bulb was worthless without power plants, transmission lines, wiring, meters, and billing systems. He spent the next decade building not bulbs but the entire electrical distribution infrastructure. The bulb was the invention. The distribution system was the business.
For AI in India, the model (Llama 4 Maverick) is the bulb. The distribution system is everything else: inference GPU infrastructure (35% of total cost), voice and speech models for 22 languages (12%), domain-specific fine-tuning (8%), application development (15%), UPI and Aadhaar integration (5%), on-device optimization for $100 smartphones (8%), user acquisition and support (12%), and regulatory compliance (5%). The model itself contributes exactly 0% of the cost - it is free. But free intelligence without distribution infrastructure is like a free light bulb without a power grid.
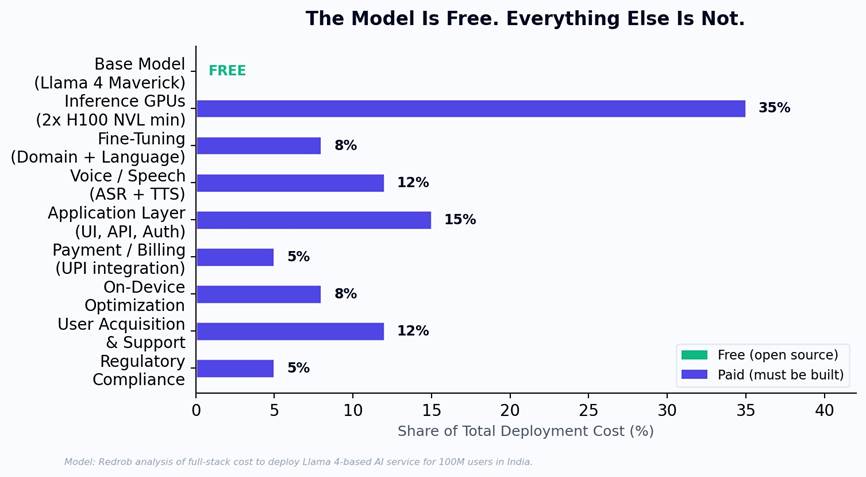
Figure 4: Full deployment cost breakdown. The model is free. Everything above it - inference, language, voice, payments, domain apps - must be built. And it constitutes 100% of the cost.
5. The Moat That Outlasts Any Model: Why Distribution Is Permanent
Here is the insight that changes the strategic calculus entirely. In the mobile era, handset hardware improved every year – faster processors, better cameras, and more memory. But the companies that owned distribution (Apple’s App Store, Google Play, and Samsung’s retail network) maintained their dominance across every hardware generation. The hardware was the commodity that improved and was replaced. The distribution was the permanent moat.
AI models will follow the same pattern. Llama 4 will be replaced by Llama 5. Llama 5 by Llama 6. Each generation will be more powerful and more efficient. But the companies that own the distribution layer – the UPI integration, the Aadhaar identity system, the voice interfaces in Tamil and Bengali, the on-device optimization for Indian smartphones, the domain expertise in Indian hiring and agriculture - will maintain their position across every model generation. The model is the part that gets replaced. The distribution is the part that compounds.
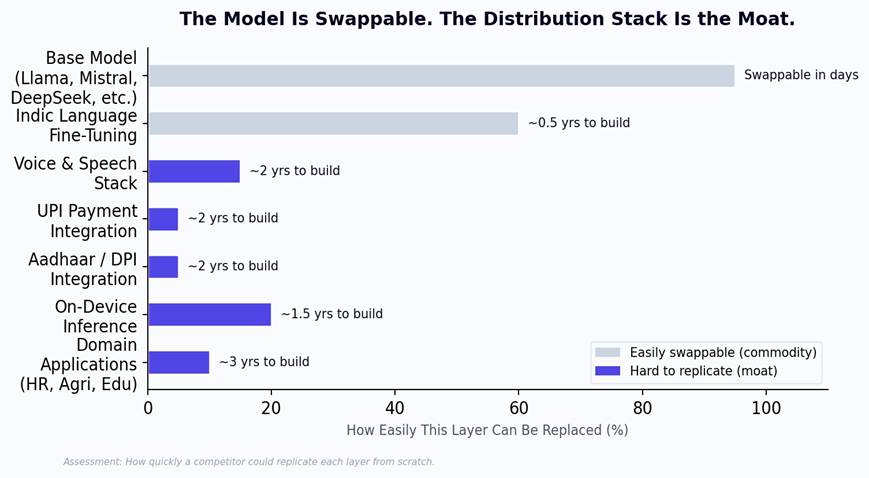
Figure 5: Swappability of each layer. The base model can be swapped in days. The distribution layers take years to build and cannot be replicated by a model upgrade.
“When Llama 5 ships, every company using Llama 4 gets the same free upgrade. None of them gets the distribution layer for free. That is where the permanent advantage lives.”
6. Redrob’s Architecture: Built on Open Source, Moated by Distribution
This is precisely why Redrob runs a 5-model ensemble (Redrob 2B, Llama 3 8B/70B/405B, Llama 4 Maverick) on AWS Bedrock. The base models are open source - leveraging the best available intelligence at the lowest possible cost. When Llama 5 ships, Redrob will integrate it. When a better open source model emerges from any lab in the world, Redrob will evaluate and adopt it. The model layer is intentionally treated as a commodity to be upgraded, not a moat to be defended.
The moat is everything above the model: multilingual intelligence across India’s scheduled languages, built through years of iteration with Indian users. On-device inference via the Redrob 2B model on $100 smartphones. UPI-native micro-transaction billing. Aadhaar-integrated identity and personalization. Domain-specific applications for HR, recruitment, and sales that understand Indian hiring practices, regional universities, and local business norms. An intelligent routing layer that matches each query to the smallest capable model - delivering 90% of frontier performance at 5% of the cost.
Llama made intelligence free. The race now is to make it accessible - to the right user, in the right language, through the right payment system, on the right device. That is not a model problem. It is a distribution problem. And distribution is the moat that outlasts every model.
