DeepSeek Proved AI Can Be Built Cheaply. It Did NOT Prove Cheap AI Can Reach 3 Billion Users.

Felix

When DeepSeek sent Nvidia’s stock down $600 billion, the world concluded AI was about to become accessible to everyone. Five gaps explain why that conclusion is wrong - and what it actually takes to bring AI to emerging markets.
In January 2025, DeepSeek released R1 - a reasoning model that matched GPT-4’s performance at a fraction of the training cost. Nvidia lost $600 billion in market cap in a single day. The narrative was instant: if AI can be built this cheaply, it will soon be accessible to everyone - including the 3 billion people in emerging markets who have been priced out of frontier AI.
Fifteen months later, that prediction has not materialized. India’s AI diffusion rate remains at 15.7% - lower than China (16.3%), Japan (19.1%), and far below Singapore (60.9%). ChatGPT has 100 million weekly active users in India yet generates a fraction of its US revenue. DeepSeek itself has been banned from government devices in eight countries, including India.
The problem is not that DeepSeek is unimpressive. Its engineering is genuinely remarkable - demonstrating that architectural innovation can achieve frontier-class performance without frontier-class budgets. That insight has permanently changed how the industry thinks about AI economics. But a cheap model and an accessible AI service are two entirely different things, separated by gaps that no amount of training efficiency can close.
1. The Domain Knowledge Gap: GPS Was Free Too
In 2005, the GPS satellite signal became freely available to every device manufacturer on Earth. The core technology - satellite-based geolocation - was completely commoditized. Yet the company that captured the overwhelming majority of mapping value was not a satellite operator. It was Google Maps, which spent a decade building the distribution layer: street-level imagery, local business listings, real-time traffic data, restaurant reviews, transit schedules. You cannot “fine-tune” a GPS signal to know that a restaurant closed last Tuesday.
The same logic applies to cheap AI models. The most common response to “DeepSeek can’t serve India” is: “just fine-tune it.” For language competence, this is correct - many teams have already fine-tuned open models for Hindi, Tamil, and Bengali. But language competence is not domain competence, just as GPS accuracy is not the same as knowing which roads are flooded during monsoon season.
Consider what it takes to build an AI hiring tool for India. The model needs to understand that an IIT Bombay degree (0.5% acceptance rate) outranks most Ivy League programs in technical rigor. It needs to know that experience at Toss, Naver, or Flipkart represents world-class product engineering even though Western ATS systems have never heard of these companies. It needs to parse resumes that mix Hindi and English mid-sentence, list qualifications from regional universities that don’t appear in any global ranking, and evaluate work experience from India’s informal sector that follows no standard format.
Or consider agricultural advisory for India’s 240 million farm workers. The model needs to understand crop rotation patterns specific to Indian states, monsoon-dependent growing seasons, government subsidy programs (PM-KISAN, PMFBY), local soil conditions, and regional pest patterns - none of which exists in DeepSeek’s training data or can be added through generic fine-tuning. This is domain knowledge that requires years of data collection, iteration with actual Indian users, and integration with local systems.
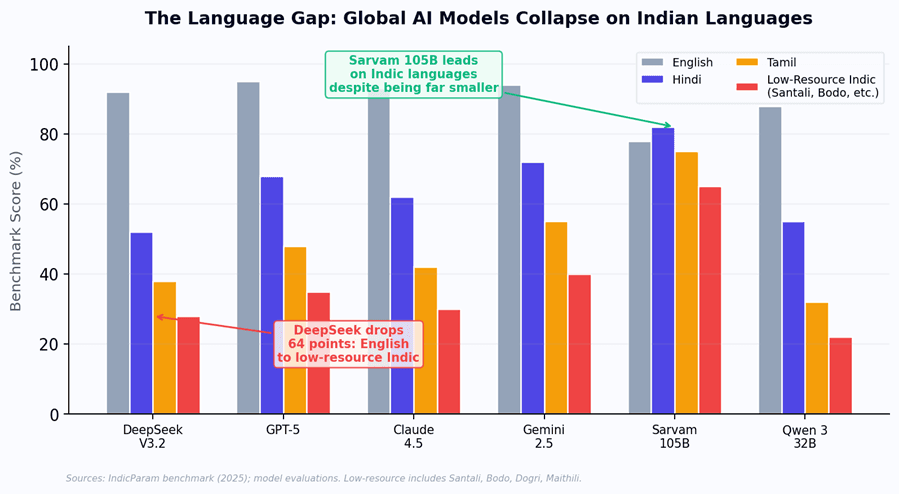
Figure 1: Even on pure language benchmarks, global models collapse on Indian languages. But language is the EASY part - domain knowledge is the real gap that fine-tuning cannot close quickly.
Language can be fine-tuned. Domain expertise cannot. It must be built - through thousands of iterations with Indian recruiters, farmers, teachers, and small business owners. This is a multi-year engineering effort, not a model swap. And it is precisely the kind of moat that cheap models cannot erode.
2. The Geopolitics Gap: The Huawei Playbook, Repeated
In 2019, Huawei offered the world’s most advanced 5G equipment at prices 20-30% below European competitors. The technology was genuinely excellent. But within three years, the UK, Australia, India, Japan, and most of Europe had banned or restricted Huawei from their telecom infrastructure - not because the equipment was inferior, but because building critical national infrastructure on technology from a geopolitical adversary created unacceptable supply chain risk. Billions of dollars of installed Huawei equipment were ripped out and replaced at enormous cost.
DeepSeek is following the same trajectory. Within seven months of its January 2025 launch, eight countries restricted or banned it from government systems: Italy, Taiwan, Australia, India, South Korea, the Netherlands, Germany, and the Czech Republic. India’s Finance Ministry prohibited it on government devices. CERT-In investigated its data collection.
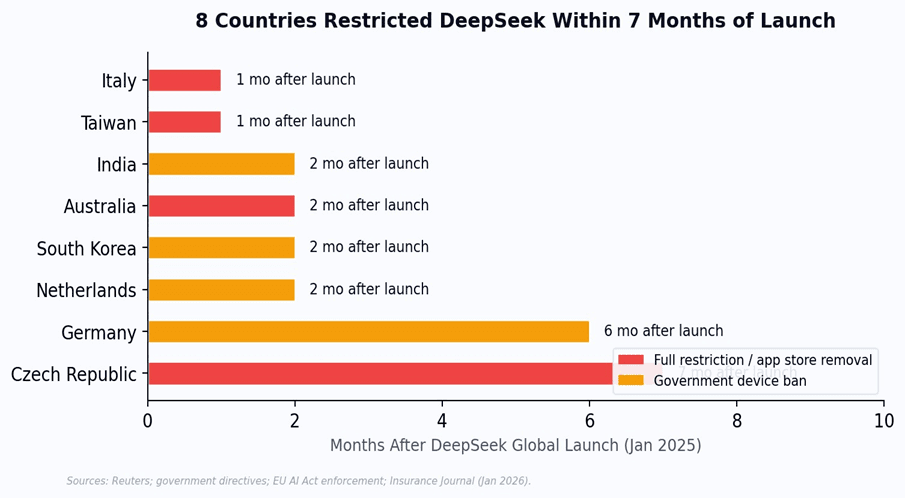
Figure 2: Timeline of government restrictions on DeepSeek following its January 2025 global launch.
The concerns are specific. Security researchers found DeepSeek’s iOS app communicates with Volcengine, ByteDance’s cloud platform. All servers are in China. India’s DPDP Act requires data handling standards that Chinese cloud APIs have not demonstrated compliance with. And India already banned 300+ Chinese apps in 2020 following border tensions - including TikTok at 200 million Indian users. Building critical AI infrastructure on Chinese models recreates the same dependency India spent five years unwinding.
3. The Distribution Infrastructure Gap: Why Android Won and Symbian Lost
In 2007, Nokia’s Symbian OS was the most widely deployed mobile operating system on Earth. It was technically mature, ran on cheap hardware, and had years of optimization. Android was an unproven, open source project. Within five years, Android had 75% market share and Symbian was dead. The difference was not the technology. It was the distribution layer: the Play Store ecosystem, Google Mobile Services, OEM partnerships, and developer tools that connected the operating system to billions of users. Symbian had the better technology. Android had the better distribution.
The same logic applies to AI in emerging markets. Even if you fine-tuned DeepSeek perfectly for every Indian language and domain, the model still sits on a server. Turning it into a service that reaches users requires distribution infrastructure that takes years to build - and is entirely independent of which model powers it.
1.Payment monetization:
UPI processes 14 billion transactions monthly. AI services targeting India must monetize through micro-transactions at Rs 10-50, not $20/month subscriptions. Building UPI-native billing, metered usage, and fraud prevention at scale is an engineering project measured in years.
2.On-device inference:
Vast areas of India have poor connectivity. Running optimized models on $100 smartphones with 3-4GB RAM requires compression, quantization, and device-specific optimization - a separate R&D effort regardless of base model.
3.Voice-first interfaces:
ASR and TTS in local accents, noisy environments, low bandwidth - this is a separate model stack entirely, not bundled with any LLM.
4.Identity integration:
Aadhaar, DigiLocker, ONDC - integrating with India’s digital public infrastructure requires regulatory compliance and API partnerships that no foreign AI company has obtained.
5.The critical insight:
none of these distribution layers care which model sits underneath. Whether you use DeepSeek, Llama, or Mistral, the distribution stack is the same multi-year effort. The model is interchangeable. The distribution is the moat.
4. The Economics Gap: Cheaper Steel Did Not Mean Cheaper Bridges
Between 1870 and 1900, the price of steel fell by 90%. The naive prediction would be that bridges and buildings became 90% cheaper. They did not. Instead, engineers used the cheap steel to build larger, more complex structures - skyscrapers, transcontinental railroads, suspension bridges - that consumed far more steel per project than anything built before. The cost per ton fell. The cost per structure rose. This is the Jevons Paradox, and it applies directly to AI.
DeepSeek’s inference is genuinely cheap - roughly $0.27 per million cached input tokens. But cheaper tokens do not mean cheaper AI tools. Reasoning models consume 10-30x more tokens per query. Agentic workflows chain hundreds of calls. Per-user serving cost stays above emerging market ARPU regardless of which model you use.
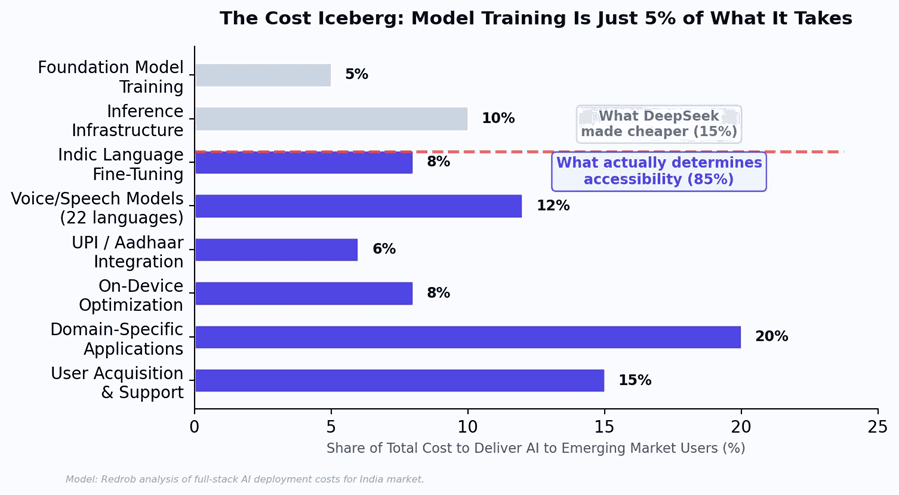
Figure 3: The cost iceberg. Model training (what DeepSeek disrupted) is 5% of total delivery cost. The other 95% is distribution infrastructure that cheap training does not touch.
Model training cost represents roughly 5% of what it takes to deliver a useful AI service to an Indian user. The remaining 95% includes inference infrastructure, language adaptation, voice models, payment integration, on-device optimization, domain applications, and user support. DeepSeek made the smallest slice cheaper. It did not touch the rest.
5. The Legal Provenance Gap: Napster Had Free Music Too
In 2000, Napster offered virtually unlimited free music. The technology worked. Millions of users loved it. But no enterprise built a business on Napster - because the legal provenance of the content was uncertain. The music industry only became a viable commercial platform when iTunes and later Spotify established clear licensing and IP chains. The lesson: free and capable technology with uncertain legal foundations cannot serve as enterprise infrastructure.
In February 2026, OpenAI submitted a formal memo to the US House Select Committee on China alleging that DeepSeek had used “distillation techniques” to “free-ride on the capabilities developed by OpenAI and other US frontier labs.” Weeks later, Anthropic publicly accused DeepSeek, Moonshot AI, and MiniMax of “industrial-scale distillation attacks,” documenting 16 million unauthorized exchanges with Claude via 24,000 fraudulent accounts. By April 2026, OpenAI, Anthropic, and Google had taken the unprecedented step of sharing attack intelligence through the Frontier Model Forum - the first coordinated defense operation between competing frontier labs.
Distillation - training a smaller model on the outputs of a larger one - is a widely used and legitimate technique in AI research. Anthropic itself acknowledged that AI firms “routinely distill their own models.” The legal question is narrower but critical: whether DeepSeek accessed frontier model outputs through unauthorized means, violating terms of service and potentially trade secret protections. As of April 2026, no litigation has been filed, and the legal framework remains unsettled.
For Indian enterprises evaluating AI infrastructure, the legal uncertainty creates a concrete adoption risk. If future enforcement actions restrict access to DeepSeek-derived models - or if regulatory pressure extends to downstream users - any system built on those foundations faces supply chain disruption. The White House AI Action Plan has called for an information sharing center on adversarial distillation. A bipartisan bill was introduced in June 2025 to bar Chinese AI from federal use. These are not hypothetical risks.
The parallel trust concerns compound the problem. DeepSeek experienced a database breach in January 2025 with no public response or user notification. Security researchers found the app communicates with ByteDance’s Volcengine cloud. For enterprises in India - where AI touches hiring, financial records, and government services - unresolved IP provenance combined with opaque data practices creates a compliance risk that no CTO can sign off on.
“The question is not whether DeepSeek’s models are capable. They clearly are. The question is whether an enterprise can build its AI infrastructure on technology whose legal provenance three frontier labs have formally challenged - and whose data practices eight governments have restricted.”
6. What Emerging Market Accessibility Actually Requires
If cheap models were sufficient, emerging markets would already have accessible AI. They do not - because accessibility requires closing all five gaps simultaneously.
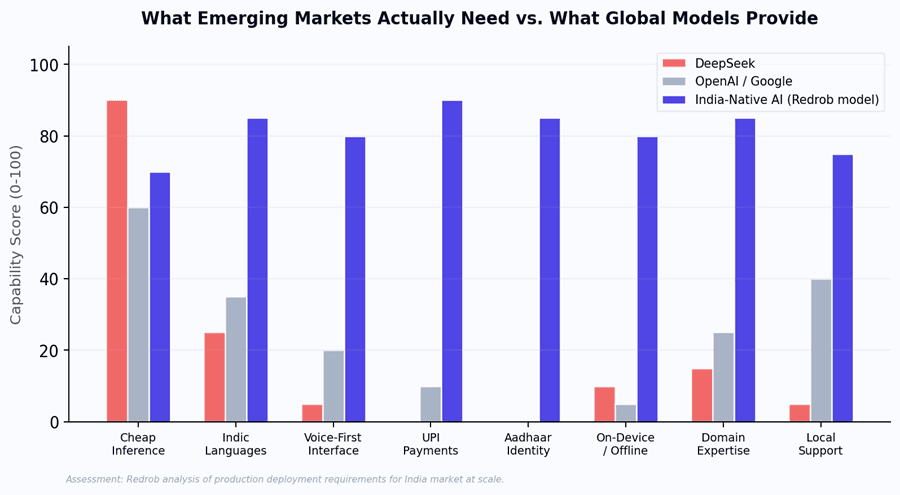
Figure 4: Capability comparison. DeepSeek excels at cheap inference but scores near zero on most distribution requirements.
India-native AI covers the full stack.
Redrob’s architecture addresses all five gaps - including the legal one. A 5-model ensemble (Redrob 2B, Llama 3 8B/70B/405B, Llama 4 Maverick) on AWS Bedrock builds exclusively on models with clear IP provenance: Meta’s Llama under its community license, plus Redrob’s own proprietary 2B model trained on licensed data. No distillation controversy. No geopolitical supply chain risk. No ambiguity about where the capabilities came from.
On top of that clean foundation, Redrob adds the distribution layers no global model provides: multilingual intelligence across India’s scheduled languages, on-device inference via Redrob 2B, UPI micro-transaction monetization, and domain-specific applications for HR, recruitment, sales, and education. It leverages cost efficiencies pioneered by the open source community - including architectural innovations that DeepSeek contributed - while building on a legal and operational foundation that enterprises can actually trust.
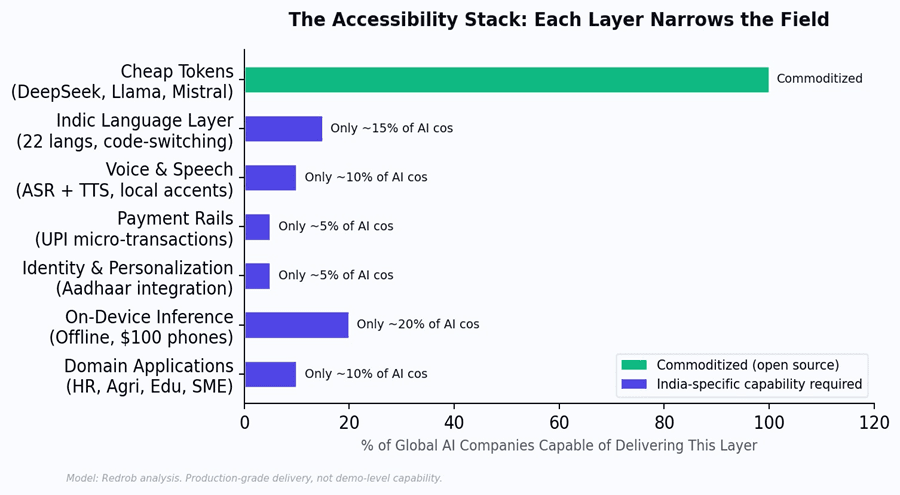
Figure5:Theaccessibilitystack.Cheaptokens(top)arecommoditized.Eachlayerbelownarrowsthefielduntilonly India-native builders remain.
DeepSeek proved frontier AI can be built cheaply. That matters. But the bottleneck to accessibility was never training cost. It was distribution, legal clarity, and trust. Getting AI to the right user, in the right language, through the right payment system, on the right device - built on foundations whose provenance enterprises can verify. Solving that requires not a cheaper model, but a different kind of company - one that builds from India, for India, on a foundation the world can trust.
